
Technology部ののっぴーです。
日頃の業務で会議の文字起こしは非常に手間がかかる作業ですが、AIで自動化することで業務効率化に大きく貢献できます。
しかし、ツールを利用する場合はファイルサイズに上限があったり、コストがかかったりするため、導入が難しいケースも考えられます。
そこで今回はより早く、より低コストで文字起こしを行う術を模索するために、「faster-whisper」という音声認識モデルによる文字起こしを試してみます。
※音声システムの開発・導入をご検討中の方へ
音声認識システムの開発に強い会社もご紹介しております。ぜひご覧ください。
faster-whisperとは
faster-whisperは、OpenAIのWhisperモデルをCTranslate2で再実装したものです。
GithubリポジトリのREADMEによると、openai/whisperと同精度にもかかわらず最大4倍高速であり、メモリ使用量も少ないのだそう。ベンチマークについても、READMEに記載されています。
構築環境
これから構築する環境を含め、各ソフト・ライブラリ・PATH等のバージョン等は以下の通りです。
| 項目 | 値 |
|---|---|
| OS | Windows 11 Pro |
| Python | 3.10.11 |
| GPU | RTX 3060Ti |
| CUDA toolkit | 11.8 |
| PowerShell | 7.3.6 (ver.7である必要はない) |
| cuDNN | 8.9.5.29 (x86_64) |
| zlib | 1.2.3 |
| プロジェクトフォルダ | ~/ws/faster-whisper |
導入
まずは下記のツールおよび依存ライブラリをインストールします。
- Python(v3.8以上)
- CUDA Toolkit(v11.8)
上記2つは、コード生成AI「WizardCoder」をローカルで動かしてみたの記事でインストール方法を解説しています。
- cuDNN 8 for CUDA 11
※導入方法はInstallation Guide – NVIDIA Docsを参照。Windowsの場合はDLしてPATHを通すだけです。
- zlib (cuDNNが依存)
ZLIB DLL Home Pageから、pre-built zlib DLL版をダウンロード。その後zipを展開して、PATHを通してください。
faster-whisperの導入は下記の通りコードを実行します(Windowsの場合)。
powershell
# プロジェクトフォルダを作成
mkdir -p path/to/project_dir
cd path/to/project_dir
# venvでpythonの仮想環境を作成しアクティベート (ここでは'myenv'として作成)
python -m venv myenv
.\myenv\Scripts\activate
# faster-whisperをインストール
pip install faster-whisper実行
faster-whisperのREADMEにあるUsageのコードを実行してみました。初回実行時にはモデルデータのダウンロードが行われます(large-v2の場合は約3GB)。
model_sizeの代わりにモデルのパスを指定することで、DL済みのモデルをそのまま使うことも可能です。
main.py
from faster_whisper import WhisperModel
model_size = "large-v2"
# Run on GPU with FP16
model = WhisperModel(model_size, device="cuda", compute_type="float16")
segments, info = model.transcribe("audio.mp3", beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))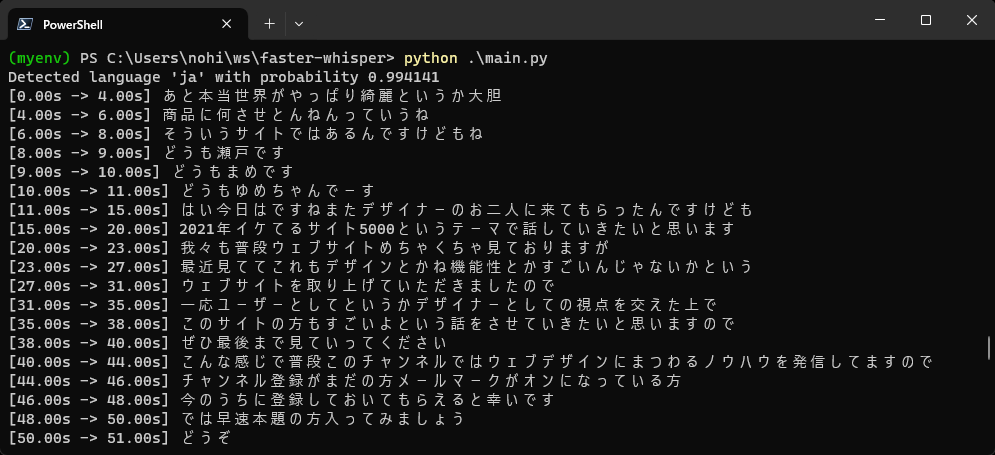
今回はデジLIGの動画(2021年版、プロが選ぶ最高にイケてるWebサイト5選!)をサンプルとして使用しました。動画の長さは8分11秒です。
処理にかかった時間ですが、beam_size=1とした場合が38秒、beam_size=5とした場合が49秒で8分11秒の音声ファイルの文字起こしが完了しました。このうち最初の6秒ほどが言語検出のための処理なので、あらかじめ言語を指定しておけばさらに時間を短縮できます。
まとめ
faster-whisperを利用することで、ローカルでコストや音声ファイルのサイズ上限を気にすることなく文字起こしを行えました。
今回GPUはRTX3600Tiを使用しましたが、もう少し性能の良いGPUを用意すればOpenAIを使うより早く、無料(初期投資と電気代を除く)で文字起こしを行う環境が構築できそうです。今回の記事がご参考になれば幸いです。
なお、弊社LIGでは、生成AIの活用に関するコンサルサービスも展開しています。
AI活用の潜在的なリスクから、実際にどのようにサービスに活用するか、システムへの実装、社内への導入や社内教育、セミナーの実施など、総合的な支援を行っております。ご興味のある方は、ぜひ気軽にお問い合わせください。











