
こんにちは、テクニカルディレクターのジョシュです。
ChatGPTをはじめとした最近のAIは、ただ単にテキストを返すだけはなく、画像や動画の中身を読み取ったり音声で会話できたりと、さまざまな種類のデータを処理することが可能になりました。
今後AIが世の中で大きな役割を担っていくためには、こういったさまざまなデータを取り扱うことができる「マルチモダリティ」が重要なキーワードになっていきます。
そこで今回は、生成AI領域の「マルチモーダルRAG」に焦点を当てて解説します。
ChatGPTやGeminiといった既存のAIモデルは高い精度を誇りますが、特定の専門分野や実務での活用には制限があることも事実です。今後AI系のサービスやアプリを開発を考える場合は、この「マルチモーダルRAG」の仕組みをある程度理解しておくことをおすすめします。
本記事では、「マルチモーダルRAG」や画像・テキスト処理の統合技術「CLIP」の基本概念の解説と、CLIPとLLM(大規模言語モデル)を組み合わせた実装例を、サンプルコードとともに紹介していきます。
▼これまでご紹介したRAG関連の記事はこちら! LangFlow ×ChatGPTを使って、AIチャットボットのRAGをノーコードで構築してみた LangChain×Streamlitを使ったチャットボットアプリを開発してみた

![]() Ranola Joshuel
Ranola Joshuel

![]() Ranola Joshuel
Ranola Joshuel
目次
「マルチモーダルRAG」とは?
マルチモーダルRAGとは、テキストデータだけはなく、画像や音声、動画といった複数のモダリティを、検索と生成のプロセスに組み込むことが可能なRAGシステムです。
従来のRAGシステムがテキストに特化しているのに対し、マルチモーダルRAGはテキスト情報と視覚・音声情報などの両方を活用することで、より包括的でコンテキストに富んだ応答を生成できるのが特徴です。
マルチモーダルRAGを構築するにあたってのパイプラインのイメージは以下です。
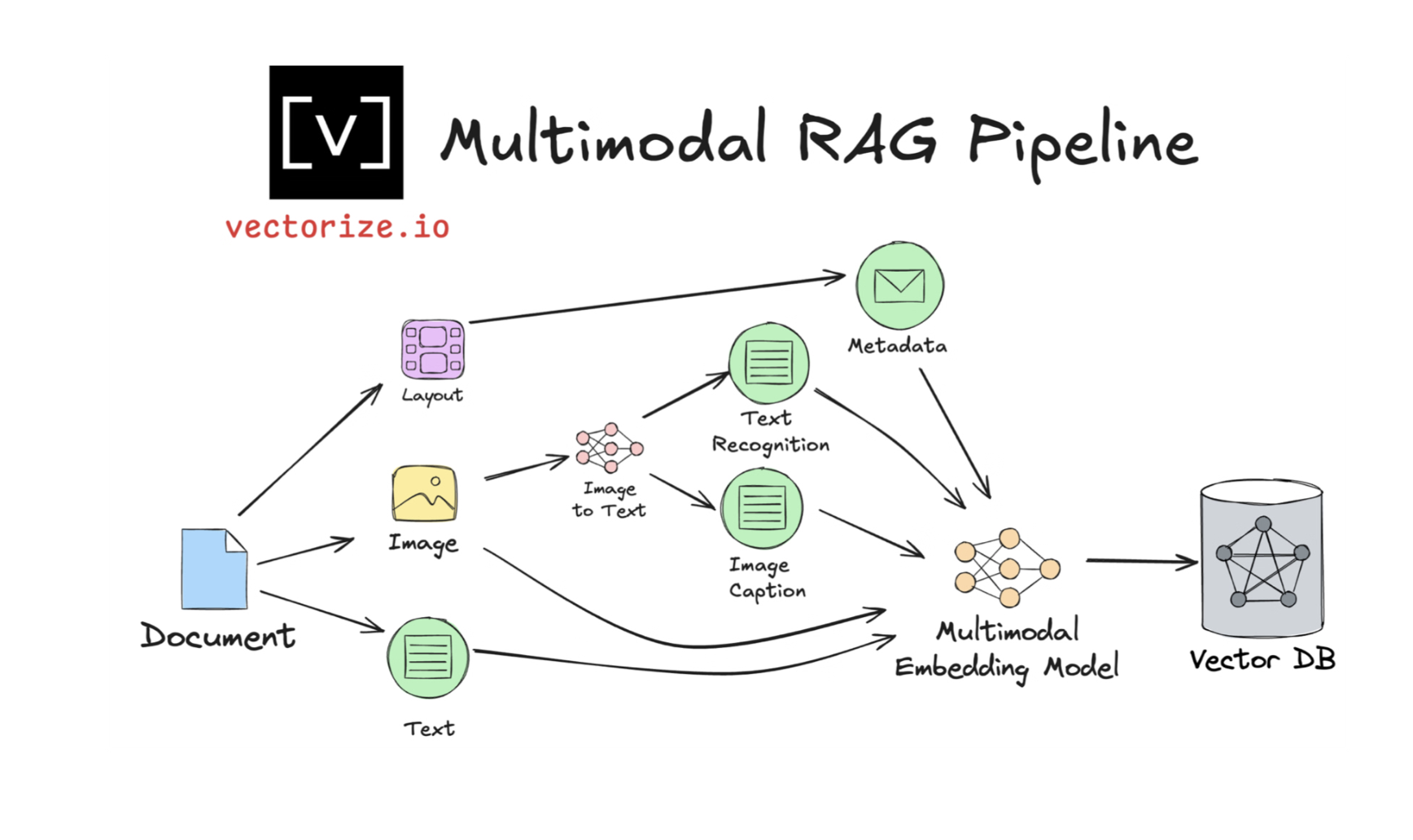 ▲出典:Multimodal RAG Patterns Every AI Developer Should Know
▲出典:Multimodal RAG Patterns Every AI Developer Should Know
「マルチモーダルRAG」の3つの実装方法
マルチモーダルRAGシステムを実装する方法はいくつかありますが、ここでは基本的な3つのアプローチを、順に高度な手法へと進む形で紹介します。
- モダリティをテキストに変換
- テキストベースの情報検索 + マルチモーダル大規模言語モデル(MLLM)
- マルチモーダル情報検索 + マルチモーダル大規模言語モデル(MLLM)
それぞれの手法が持つ特性を理解しながら、システム設計に適した戦略を選択することが重要です。
1. モダリティをテキストに変換
RAGシステムをマルチモーダル対応にするシンプルな方法は、新しいモダリティをテキストに変換してからナレッジベースに格納することです。
具体的には、会議録音をテキストの書き起こしに変換したり、既存のマルチモーダルLLM(MLLM)を活用して画像キャプションを生成したり、表形式のデータを.csvや.jsonなど読みやすいテキスト形式に変換するなどの方法があります。
2. テキストベースの情報検索 + マルチモーダル大規模言語モデル(MLLM)
別のアプローチとして、ナレッジベース内のすべての項目に対してテキスト表現(説明文やメタタグなど)を生成し、検索に活用する方法があります。
ただし、推論時には元のモダリティデータ(画像や音声)をマルチモーダルLLM(MLLM)に渡します。たとえば、画像検索ではメタデータを使用して該当データを検索し、推論処理では関連する画像自体をモデルに入力する形です。
3. マルチモーダル情報検索 + マルチモーダル大規模言語モデル(MLLM)
レベル1やレベル2の検索プロセスではキーワード検索を使用することも可能ですが、一般的には「ベクトル検索」が用いられます。
これは、ナレッジベース内の各項目をベクトル表現(埋め込み)に変換し、入力クエリと各項目の類似度スコアを計算して検索を行う手法です。ベクトル検索を活用することで、より柔軟かつ精度の高い検索が可能になります。
「CLIP」とは?
「CLIP(Contrastive Language-Image Pretraining)」とは、OpenAIが開発した画像とテキストの関係性を理解できる事前学習済みのマルチモーダルAIモデルです。CLIPは、テキストによる学習を通じて、画像の特徴やパターンを効率的に理解できる仕組みを持っています。
CLIPは、画像とテキストのペアを入力として受け取り、両者の関係性を学習空間の中で理解します。具体的には、画像を理解する部分(画像エンコーダー)とテキストを理解する部分(テキストエンコーダー)が連携して学習を行い、正しい組み合わせの類似度を高め、間違った組み合わせの類似度を低くするように調整します。
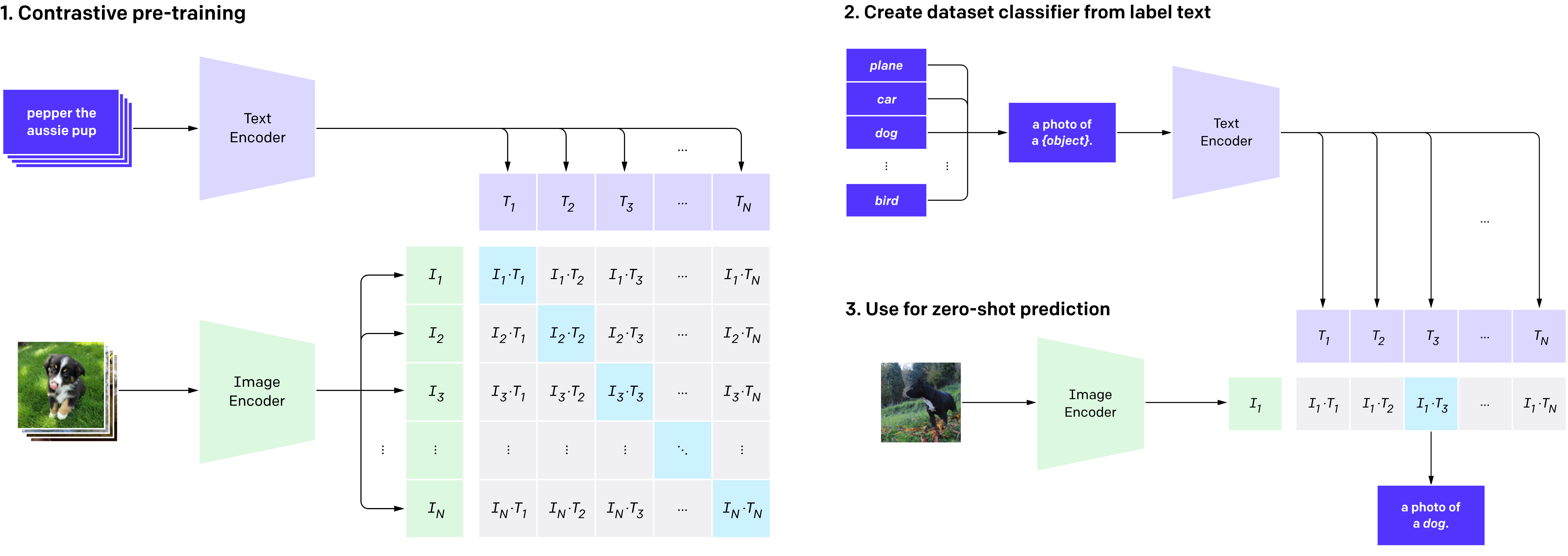 ▲CLIPのトレーニングアーキテクチャ(参考画像)
▲CLIPのトレーニングアーキテクチャ(参考画像)
「CLIP」の特徴
- コントラスト学習
- データに基づく分類の仕組み
- ゼロショット予測
4億組もの画像とテキストのペアを使って学習を行い、正しい組み合わせと間違った組み合わせを区別できるようになります。この過程で、画像とテキストの特徴を共通の理解空間として形成します。
各画像に対して、正しい説明文と間違った説明文を用意します。テキスト理解部分がそれぞれの特徴を抽出し、正しい組み合わせをより強く、間違った組み合わせをより弱く結びつけるように学習します。
学習を終えたCLIPは、見たことのない新しい画像でも即座に分類できます。画像とテキストの類似度を計算し、もっとも関連性の高い分類を予測します。
「マルチモーダルRAG」で質問応答アシスタントを構築してみた
マルチモーダルRAGの基本の仕組みを理解したところで、実際にこのシステムを構築してみます。
今回は、テキストや図表にアクセスできる「質問応答型のアシスタント」を作ります。
ここではコードの重要なポイントだけを説明しますので、すべてのコードを試してみたい場合は、私のGitHubリポジトリをご覧ください。
作成したPythonコードのノートブックは自由にご利用いただけますのでぜひ作ってみてください!
1. 環境準備
まずは、お使いのPCにOllamaをダウンロードしましょう。公式サイトから簡単にダウンロードできます!
次に、便利なライブラリやモジュールをいくつかインポートしていきます。
pip install ollama
import json from functions import * from transformers import CLIPProcessor, CLIPModel from torch import load, matmul, argsort from torch.nn.functional import softmax from IPython.display import Image import ollama
こちらのブログ記事「LangFlow×ChatGPT」から、テキストと画像のチャンクをインポートします。これらは.jsonファイルとして保存されており、Pythonで辞書のリストとして簡単に読み込むことができます。
# 記事内容を読み込む
text_content_list = load_from_json('data/text_content.json')
image_content_list = load_from_json('data/image_content.json')
また、text_content_listやimage_content_list内の各項目に対して、マルチモーダル埋め込み(CLIPから生成されたもの)も読み込みます。これらはPyTorchのテンソルとして保存されています。
# 埋め込みを読み込む
text_embeddings = load('data/text_embeddings.pt', weights_only=True)
image_embeddings = load('data/image_embeddings.pt', weights_only=True)
torch.Size([38, 512]) torch.Size([11, 512])
これらのテンソルの形状を確認すると、512次元の埋め込みとして表現されていることがわかります。また、テキストチャンクが38個、画像が11個含まれています。
2. マルチモーダル検索の実装
ナレッジベースの準備が整ったので、次はベクトル検索のクエリを定義します。これは、OpenAIのCLIPを使用して、入力クエリを埋め込みに変換するプロセスから始まります。
# クエリの定義
query = "RAGのアーキテクチャとは?"
# クエリを埋め込みに変換する(4ステップ)
# 1) モデルのロード
model = CLIPTextModelWithProjection.from_pretrained("openai/clip-vit-base-patch16")
# 2) データプロセッサのロード
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch16")
# 3) テキストの前処理
inputs = processor(text=[query], return_tensors="pt", padding=True)
# 4) CLIPを使用して埋め込みを計算
outputs = model(**inputs)
# 埋め込みを抽出
query_embed = outputs.text_embeds
クエリを表す単一のベクトルが生成されたことが、形状を確認することでわかります。
ナレッジベースでベクトル検索を実行するには、以下の手順を行います。
- クエリ埋め込みとすべてのテキストおよび画像埋め込み間の類似度を計算する。
- ソフトマックス関数を使用して、類似度を0から1の範囲にスケーリングする。
- スケーリングされた類似度をソートし、上位k件の結果を返す。
- あらかじめ定義された類似度のしきい値を超える項目のみをフィルタリングする。
以下に、テキストチャンクに対するコード例を示します。
k = 5 threshold = 0.1 # 記事に対するマルチモーダル検索 text_similarities = matmul(query_embed, text_embeddings.T) image_similarities = matmul(query_embed, image_embeddings.T) # ソフトマックスで類似度を再スケーリング temp=0.25 text_scores = softmax(text_similarities/temp, dim=1) image_scores = softmax(image_similarities/temp, dim=1) # 上位k件のフィルタリングされたテキスト結果を返す isorted_scores = argsort(text_scores, descending=True)[0] sorted_scores = text_scores[0][isorted_scores] itop_k_filtered = [idx.item() for idx, score in zip(isorted_scores, sorted_scores) if score.item() >= threshold][:k] top_k = [text_content_list[i] for i in itop_k_filtered] top_k # 結果を表示 print(top_k)
# top_kの結果
[{'article_title': 'Untitled',
'section': 'RAGのアーキテクチャ',
'text': 'ドキュメントの読み込み:最初に、文書やデータソースをロードします。チャンクへの分割:文書を扱いやすいサイズに分割します。エンベディングの生成: 分割した各チャンクをエンベディングを使ってベクトル表現に変換します。ベクターデータベースへの保存: これらのベクトルをベクターデータベースに保存し、効率的に検索できるようにします。ユーザーとのインタラクション: ユーザーからのクエリや入力を受け取り、エンベディングに変換します。ベクターデータベースでのセマンティック検索: ユーザーのクエリに基づいてベクターデータベースでセマンティック検索を行います。レスポンスの取得と処理: 関連するレスポンスを取得し、それを大規模言語モデル(LLM)で処理して回答を生成します。ユーザーへの回答の提供: LLMによって生成された最終的な回答をユーザーに提示します。'},
{'article_title': 'Untitled',
'section': 'RAGのアーキテクチャ',
'text': '画像出典:https://newsletter.nocode.ai/p/guide-retrieval-augmented-generationこちらの画像で説明されているように、RAGのアーキテクチャは通常、以下の8つのステップを含みます。'}]
上記では、上位のテキスト検索結果が表示されています。ただし、k=5に設定しているにもかかわらず、1件しか結果がありません。これは、2位から5位の項目が類似度の閾値である0.1を下回っていたためです。
この結果は初期のクエリ「RAGのアーキテクチャとは?」に対して有益ではないように見えます。これは、ベクター検索の主要な課題の1つを浮き彫りにしています。つまり、クエリに類似している項目が必ずしもその答えを導く助けになるとは限らない、という点です。
この問題を軽減する1つの方法は、検索結果に対する制約を緩和することです。具体的には、kを増やし、類似度の閾値を下げることで、結果を広げ、LLM(大規模言語モデル)が有益な情報とそうでない情報を見分けることを期待するアプローチが考えられます。
これを実現するために、まずベクター検索の手順をPython関数にまとめてみます。
def similarity_search(query_embed, target_embeddings, content_list, k=5, threshold=0.05, temperature=0.5):
"""
埋め込みベクトルを使用して類似度検索を実行
"""
# 類似度を計算
similarities = torch.matmul(query_embed, target_embeddings.T)
# ソフトマックスで類似度を再スケーリング
scores = torch.nn.functional.softmax(similarities/temperature, dim=1)
# ソートされたインデックスとスコアを取得
sorted_indices = scores.argsort(descending=True)[0]
sorted_scores = scores[0][sorted_indices]
# 閾値でフィルタリングし、上位k件を取得
filtered_indices = [
idx.item() for idx, score in zip(sorted_indices, sorted_scores)
if score.item() >= threshold
][:k]
# 対応するコンテンツ項目とスコアを取得
top_results = [content_list[i] for i in filtered_indices]
result_scores = [scores[0][i].item() for i in filtered_indices]
return top_results, result_scores
この設定により、テキストの結果が4件、画像の結果が1件得られます。
テキストの結果
1 - ドキュメントの読み込み:最初に、文書やデータソースをロードします。チャンクへの分割: 文書を扱いやすいサイズに分割します。エンベディングの生成: 分割した各チャンクをエンベディングを使ってベクトル表現に変換します。ベクターデータベースへの保存: これらのベクトルをベクターデータベースに保存し、効率的に検索できるようにします。ユーザーとのインタラクション: ユーザーからのクエリや入力を受け取り、エンベディングに変換します。ベクターデータベースでのセマンティック検索: ユーザーのクエリに基づいてベクターデータベースでセマンティック検索を行います。レスポンスの取得と処理: 関連するレスポンスを取得し、それを大規模言語モデル(LLM)で処理して回答を生成します。ユーザーへの回答の提供: LLMによって生成された最終的な回答をユーザーに提示します。 2 - 画像出典:https://newsletter.nocode.ai/p/guide-retrieval-augmented-generationこちらの画像で説明されているように、RAGのアーキテクチャは通常、以下の8つのステップを含みます。 3 - そもそも「RAG」とは?RAGのアーキテクチャさっそく実験してみた前提LangFlowのインストール方法構築のヒントLangflowから作成したフローをWebウィジェット(HTML)に変換してみるまとめ 4 - 以前にPython言語でLangchain、StreamlitとChatGPTモデルを活用してRAGを作成しました。以下の記事で解説していますので、ぜひご覧ください。
画像の結果
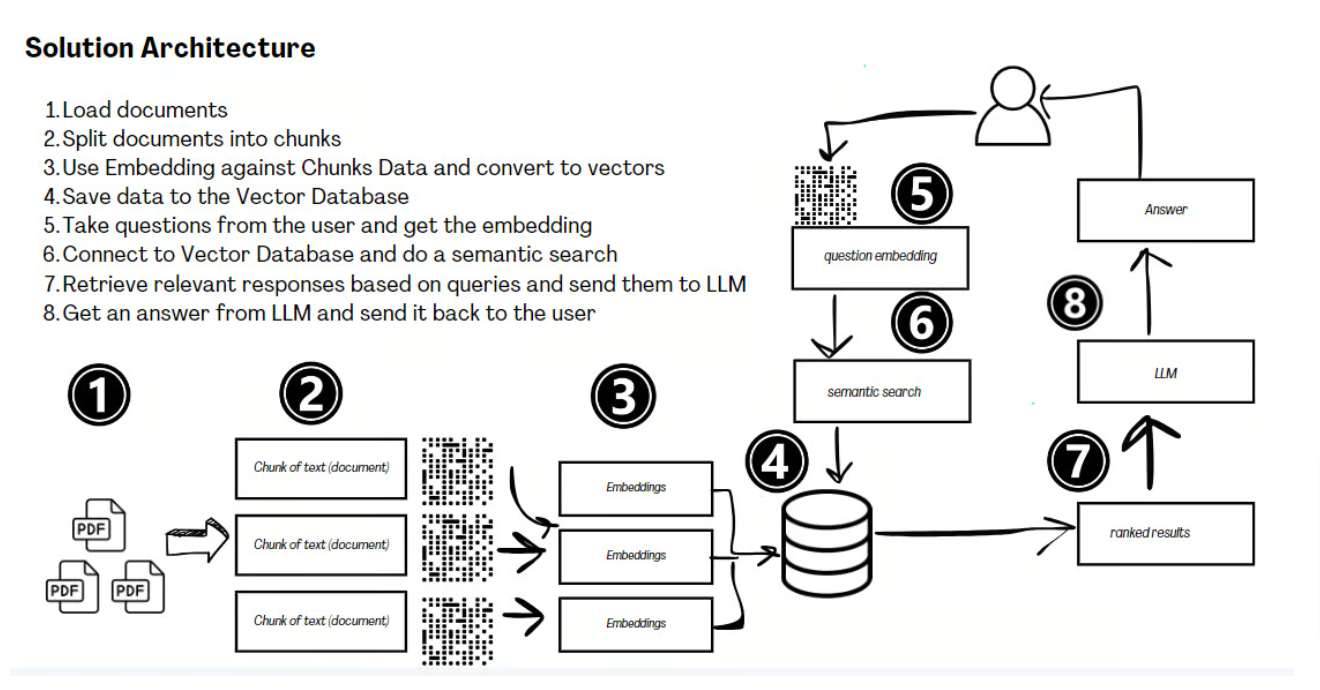
3. LLMを使用した回答生成
テキスト項目の多くはクエリに対してあまり有用ではないように見えますが、画像の結果はまさに求めていたものです。それでも、この検索結果を基に、LLaMA 3.2 Visionがこのクエリにどのように応答するかを確認してみましょう。
まずは、検索結果を適切にフォーマットされた文字列として構造化します。
テキストのフォーマット
text_context = ""
for text in text_results:
if text_results:
text_context = text_context + "**記事タイトル:** " + text['article_title'] + "\n"
text_context = text_context + "**セクション:** " + text['section'] + "\n"
text_context = text_context + "**スニペット:** " + text['text'] + "\n\n"
画像のフォーマット
image_context = ""
for image in image_results:
if image_results:
image_context = image_context + "**記事タイトル:** " + image['article_title'] + "\n"
image_context = image_context + "**セクション:** " + image['section'] + "\n"
image_context = image_context + "**画像パス:** " + image['image_path'] + "\n"
image_context = image_context + "**画像キャプション:** " + image['caption'] + "\n\n"
各テキストおよび画像項目に付随するメタデータに注目してください。これにより、LLaMAがコンテンツの文脈をより良く理解できるようになります。
次に、テキストと画像の結果をプロンプト内で交互に配置していきます。
# プロンプトテンプレートを作成
prompt = f"""以下の質問「{query}」と、関連するスニペットが提供されています。
{text_context}
{image_context}
提供されたスニペットから得られる情報を基に、簡潔で正確な回答を作成してください。
"""
生成されたプロンプト
以下の質問「RAGのアーキテクチャとは?」と、関連するスニペットが提供されています。 **記事タイトル:** Untitled **セクション:** RAGのアーキテクチャ **スニペット:** ドキュメントの読み込み:最初に、文書やデータソースをロードします。チャンクへの分割: 文書を扱いやすいサイズに分割します。エンベディングの生成: 分割した各チャンクをエンベディングを使ってベクトル表現に変換します。ベクターデータベースへの保存: これらのベクトルをベクターデータベースに保存し、効率的に検索できるようにします。ユーザーとのインタラクション: ユーザーからのクエリや入力を受け取り、エンベディングに変換します。ベクターデータベースでのセマンティック検索: ユーザーのクエリに基づいてベクターデータベースでセマンティック検索を行います。レスポンスの取得と処理: 関連するレスポンスを取得し、それを大規模言語モデル(LLM)で処理して回答を生成します。ユーザーへの回答の提供: LLMによって生成された最終的な回答をユーザーに提示します。 **記事タイトル:** Untitled **セクション:** RAGのアーキテクチャ **スニペット:** 画像出典:https://newsletter.nocode.ai/p/guide-retrieval-augmented-generationこちらの画像で説明されているように、RAGのアーキテクチャは通常、以下の8つのステップを含みます。 **記事タイトル:** Untitled **セクション:** Main **スニペット:** そもそも「RAG」とは?RAGのアーキテクチャさっそく実験してみた前提LangFlowのインストール方法構築のヒントLangflowから作成したフローをWebウィジェット(HTML)に変換してみるまとめ **記事タイトル:** Untitled **セクション:** RAGのアーキテクチャ **スニペット:** 以前にPython言語でLangchain、StreamlitとChatGPTモデルを活用してRAGを作成しました。以下の記事で解説していますので、ぜひご覧ください。 **記事タイトル:** Untitled **セクション:** Langflowから作成したフローをWebウィジェット(HTML)に変換してみる **画像パス:** images/rag2.png **画像キャプション:** No caption available 提供されたスニペットから得られる情報を基に、簡潔で正確な回答を作成してください。
最後に、Ollamaを使用してこのプロンプトをLLaMA 3.2 Visionに渡します。あらかじめPCにOllamaがインストールされ、起動していることを確認してください。
また、プロンプトに「日本語で返答してください」などを追加することも忘れないでください。
ollama.pull('llama3.2-vision')
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': f"以下の指示に従って回答してください。日本語で返答してください: {prompt}",
'images': [image["image_path"] for image in image_results]
}]
)
print(response['message']['content'])
LLMの実行結果
RAG (Retrieval-Augmented Generation) アーキテクチャとは、以下の8つのステップを含むデータ処理アプローチです。 1. ドキュメントの読み込み:最初に、文書やデータソースをロードします。 2. チャンクへの分割: 文書を扱いやすいサイズに分割します。 3. エンベディングの生成: 分割した各チャンクをエンベディングを使ってベクトル表現に変換します。 4. ベクターデータベースへの保存: これらのベクトルをベクターデータベースに保存し、効率的に検索できるようにします。 5. ユーザーとのインタラクション: ユーザーからのクエリや入力を受け取り、エンベディングに変換します。 6. ベクターデータベースでのセマンティック検索: ユーザーのクエリに基づいてベクターデータベースでセマンティック検索を行います。 7. レスポンスの取得と処理: 関連するレスポンスを取得し、それを大規模言語モデル(LLM)で処理して回答を生成します。 8. ユーザーへの回答の提供: LLMによって生成された最終的な回答をユーザーに提示します。 RAGは、質問に基づいて関連する情報を検索し、それらの情報を大規模言語モデル(LLM)で処理して回答を生成することを目的としたアプローチです。
ご覧のとおり、モデルは正確に画像が情報を含んでいることを認識し、日本語でうまく説明することができました。
まとめ
CLIPは、画像とテキストのペアを活用して視覚と言語を結びつける革新的なモデルで、未学習のオブジェクトも予測可能なゼロショット能力を持っています。一方、マルチモーダルRAGは、CLIPによる視覚情報とLLM(大規模言語モデル)によるテキスト処理を組み合わせることで、異なる形式のデータを統合し、幅広い知識活用を可能にします。
今回の実装例では成果を確認できましたが、検索精度向上にはリランカーの導入や埋め込みの最適化が有効です。
CLIPが提供する視覚と言語の統合能力と、マルチモーダルRAGの柔軟な知識統合機能に加え、LLMの強力なテキスト生成能力を組み合わせることで、より高度で包括的なAIソリューションが実現します。この組み合わせにより、多様な応用の可能性が広がり、今後さらに多くの活用例が期待されます。
この記事が、みなさんのお役に立てれば嬉しいです!
「生成AIについて社内で理解を深めたいけど、どう進めていいかわかない」「生成AIの業務効率化について具体的な事例やアドバイスが欲しい」などご興味のある企業さまは、下記ページからお気軽にご相談ください。









