
Technology部のJoshです。
今回は画像生成AI「Stable Diffusion(ステイブル・ディフュージョン)」で、実際に画像を作る手順をていねいに解説します。はじめて使ってみる方の参考になれば幸いです。
※画像認識AIの開発・導入を検討中の方はおすすめの画像認識AI開発会社まとめもご覧ください。
概要
Stable Diffusionとは
「Stable Diffusion」とは、入力されたテキスト(プロンプト)から高品質な画像を生成するAIモデルです。人物や動物、風景など、さまざまな画像を生成できます。また、リアルで創造的な画像を生成する能力でも知られています。
Stable Diffusionは、「ランダムな画像にノイズを加えて、徐々にプロンプトに一致させていく」という拡散プロセスをもとにしています。画像がプロンプトとどの程度一致するかを評価し、一致しない場合はノイズを取り除く。一致する場合は追加しない。このプロセスを、画像とプロンプトが十分一致するまで繰り返します。
AUTOMATIC1111 Stable Diffusion WebUIとは
「AUTOMATIC1111 Stable Diffusion WebUI」は、Stable Diffusionをブラウザで簡単に使用できるようになるユーザーインターフェースです。プロンプトの入力、生成された画像のプレビューが可能です。
なお、「AUTOMATIC1111 Stable Diffusion WebUI」を使用するためには、PythonとGitをインストールする必要があります。
手順
1.インストール
GitHubから「AUTOMATIC1111 Stable Diffusion WebUI」リポジトリをクローンします。
terminal
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
stable-diffusion-webuiディレクトリに移動します。
terminal
cd stable-diffusion-webui
Webインターフェイスを起動するには、webui.shスクリプトを実行します。
terminal
./webui.sh
Webインターフェイスが実行されたら、ブラウザーで http://127.0.0.1:7860 にアクセスしましょう(URLは異なる場合があります)。
ターミナルで cmd + クリックを使用している場合は、次のリンクをクリックしてください。
Running on local URL: https://127.0.0.1:7860
Webインターフェイスのトップページには、プロンプトを入力するためのテキストボックスと、生成された画像をプレビューするための画像ビューワーが表示されます。
たとえば、プロンプトに 「美しい猫の絵」 と入力すると次のような画像が生成されました。保存ボタンをクリックするとPNGファイルとしてダウンロード可能です。
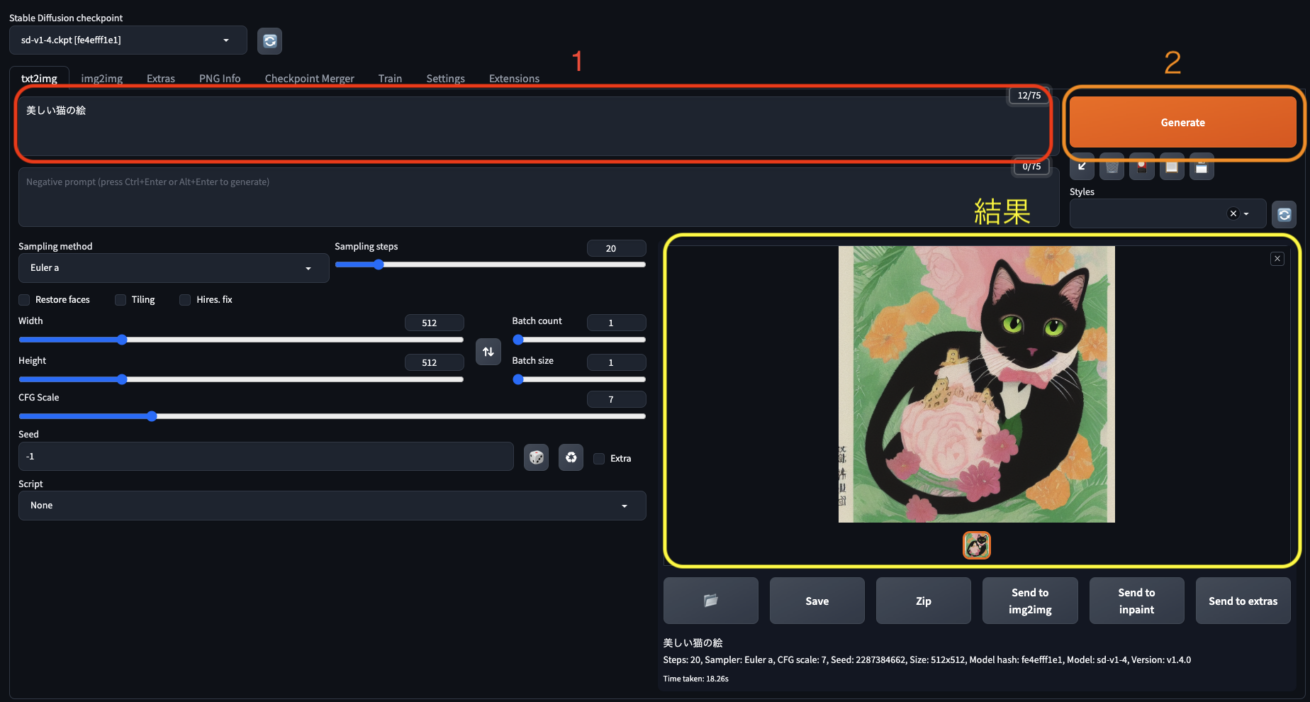
生成された画像に満足できない場合は、プロンプトを変更して、生成ボタンをもう一度クリックしましょう。また、設定パネルから生成プロセスを調整することもできます。
2.モデルの追加方法
「AUTOMATIC1111 Stable Diffusion WebUI」にはいくつかのプレトレーニングモデルが付属していますが、カスタムモデルを追加することもできます。
モデルを探すのにもっともオススメのサイトは「Civitai」です。実際のイラストを見ながら選べるため、好みのモデルを簡単に見つけることができます。画像をクリックすると、即座にダウンロードがスタート。アカウント作成も不要です。
※アカウントを作成してログインすると18歳以上のモデルにアクセスできるようになりますが、今回は使用しません。
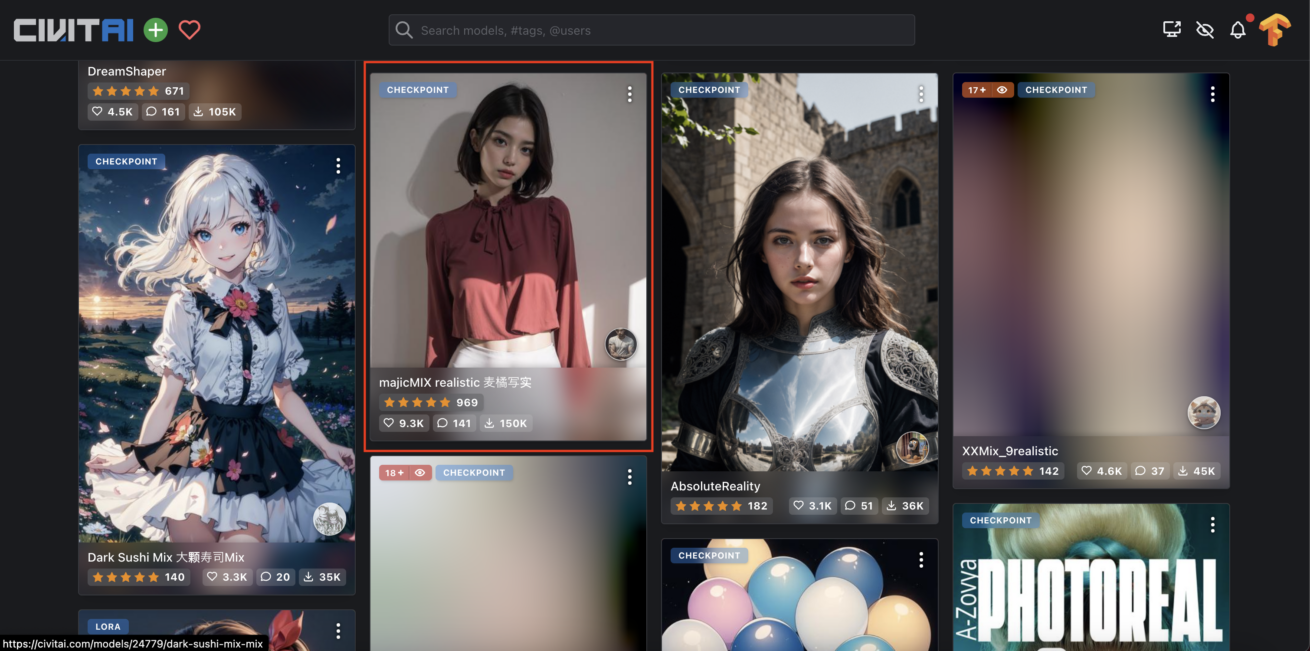
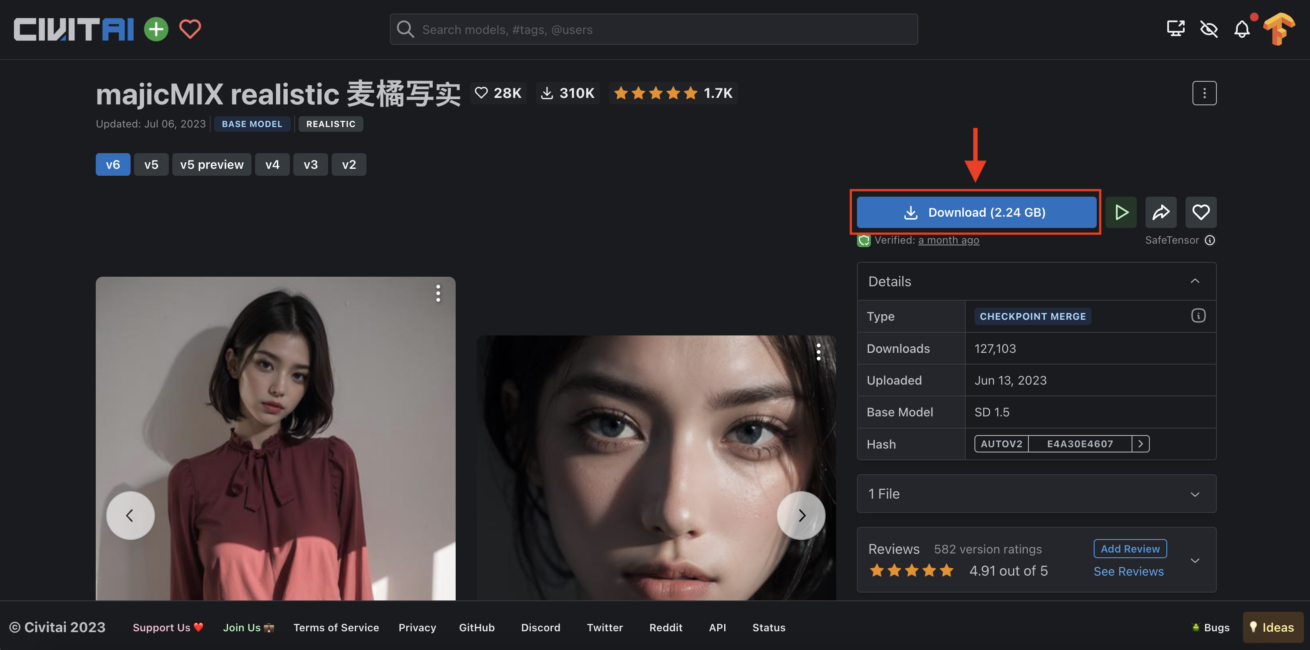
例として、 「magicMIX Realistic」 のモデルを選択しました。右上の青いボタンをタップするだけで、簡単にモデルを入手することができます。
ダウンロードしたファイルを解凍し、ダウンロードしたファイルをstable-diffusion-webuiディレクトリのmodels/Stable-diffusionディレクトリにコピーします。
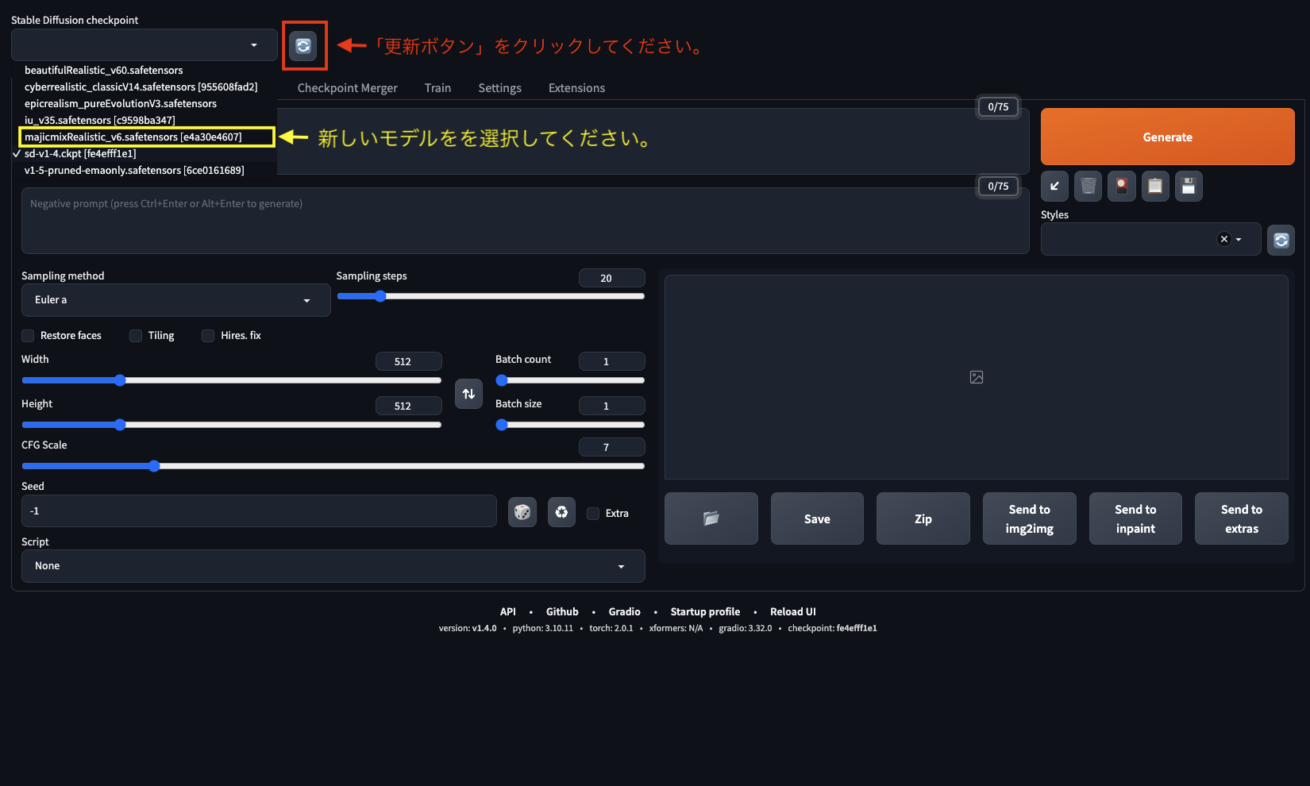
左上の更新ボタンをクリックして、新しく追加されたモデルを選択しましょう。しばらく待つと、モデルの切り替えが可能になります。
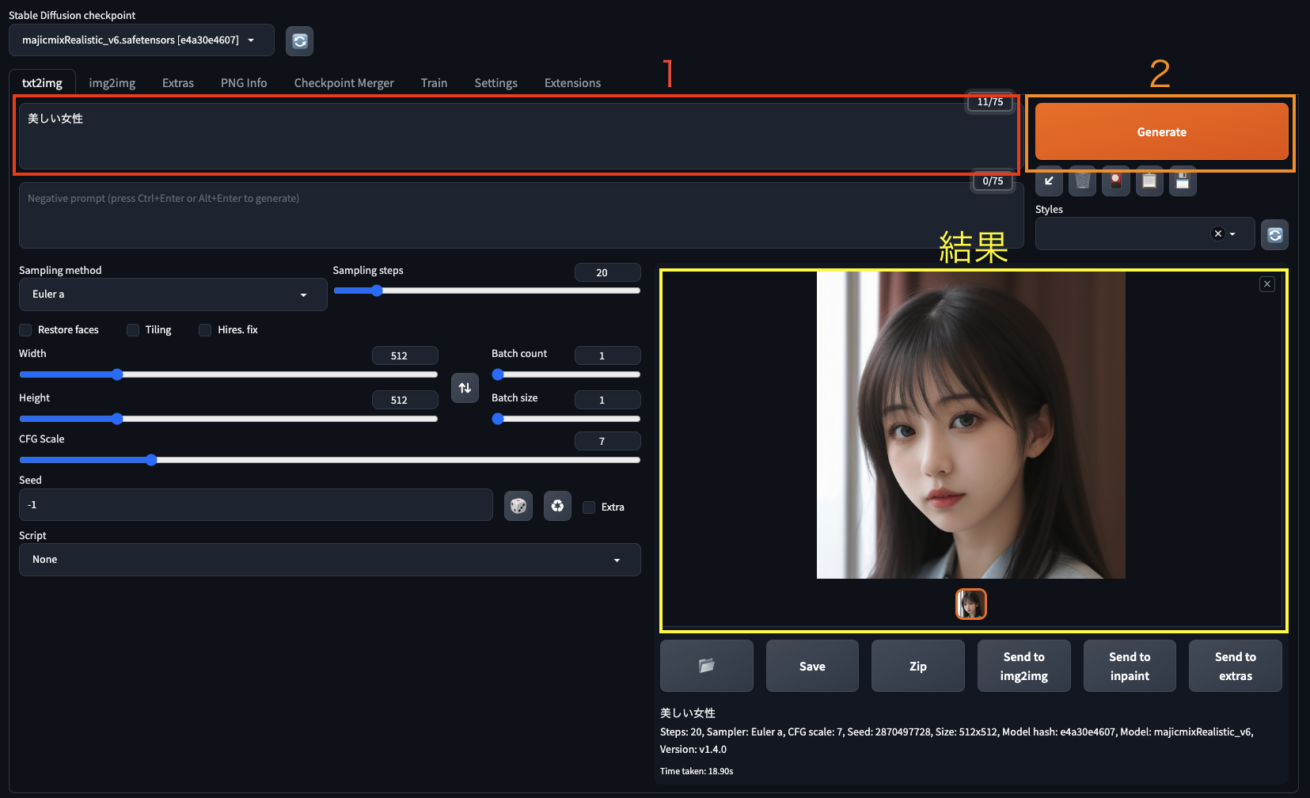
たとえば、プロンプトに 「美しい女性」 と入力すると次のような画像が生成されました。
また、モデルを探すときは「Hugging Face」というサイトもおすすめです。ぜひチェックしてみてください。
3.画像をベースに生成する方法
Stable Diffusionでのイラスト生成には、おもに「txt2img」という手法が使われています。しかし「テキスト」をベースにしているため、思い通りのイラストを作ることが難しい場合があります。
そんな悩みを解決してくれるのが、「img2img」です。「画像」をベースに新しいイラストを生成するため、より細かなニュアンスを指示することができ、より理想に近いイラストを作成することができます。
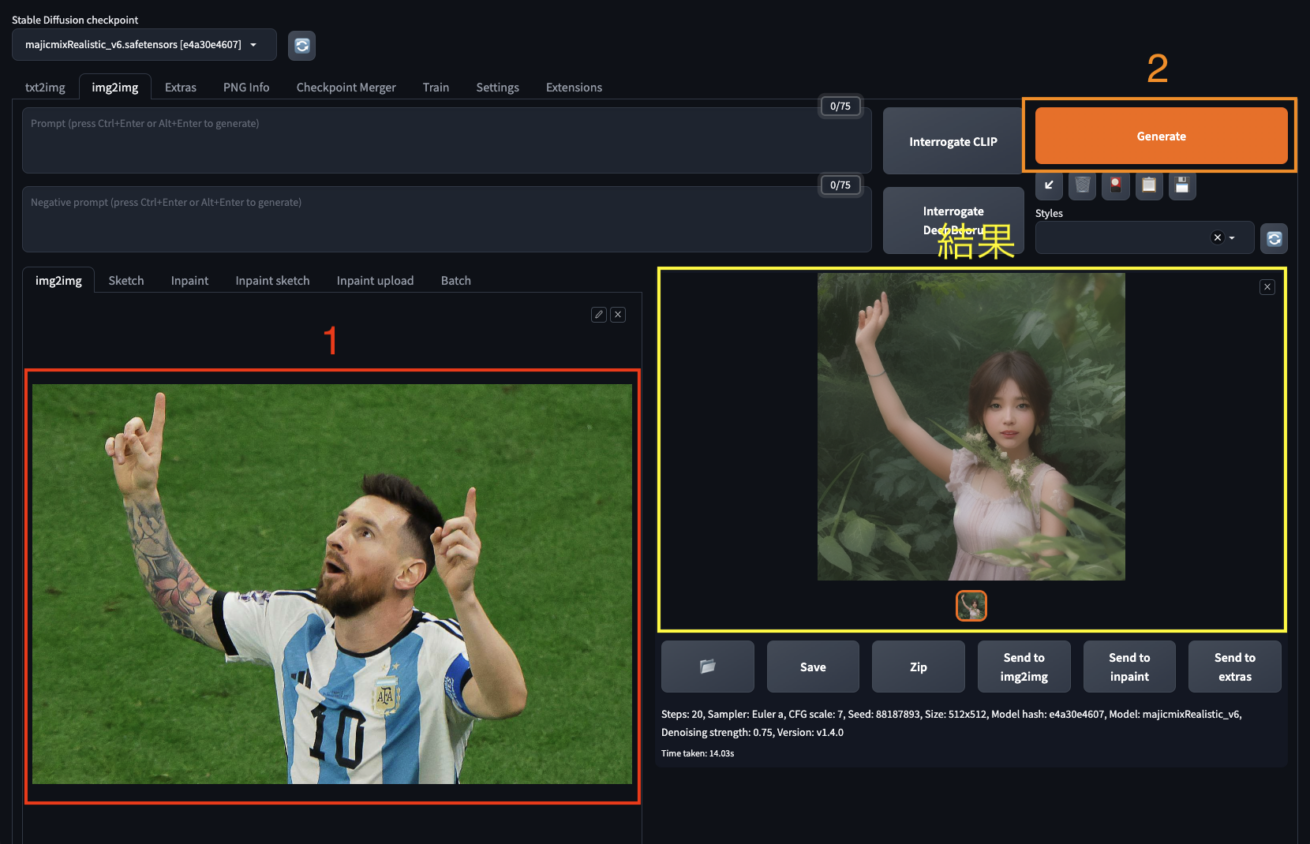
「img2img」というタブをクリックし、まずは適当な画像で試してみましょう。「Generate」ボタンをクリックすると、結果が表示されます(モデルによって結果は異なります)。
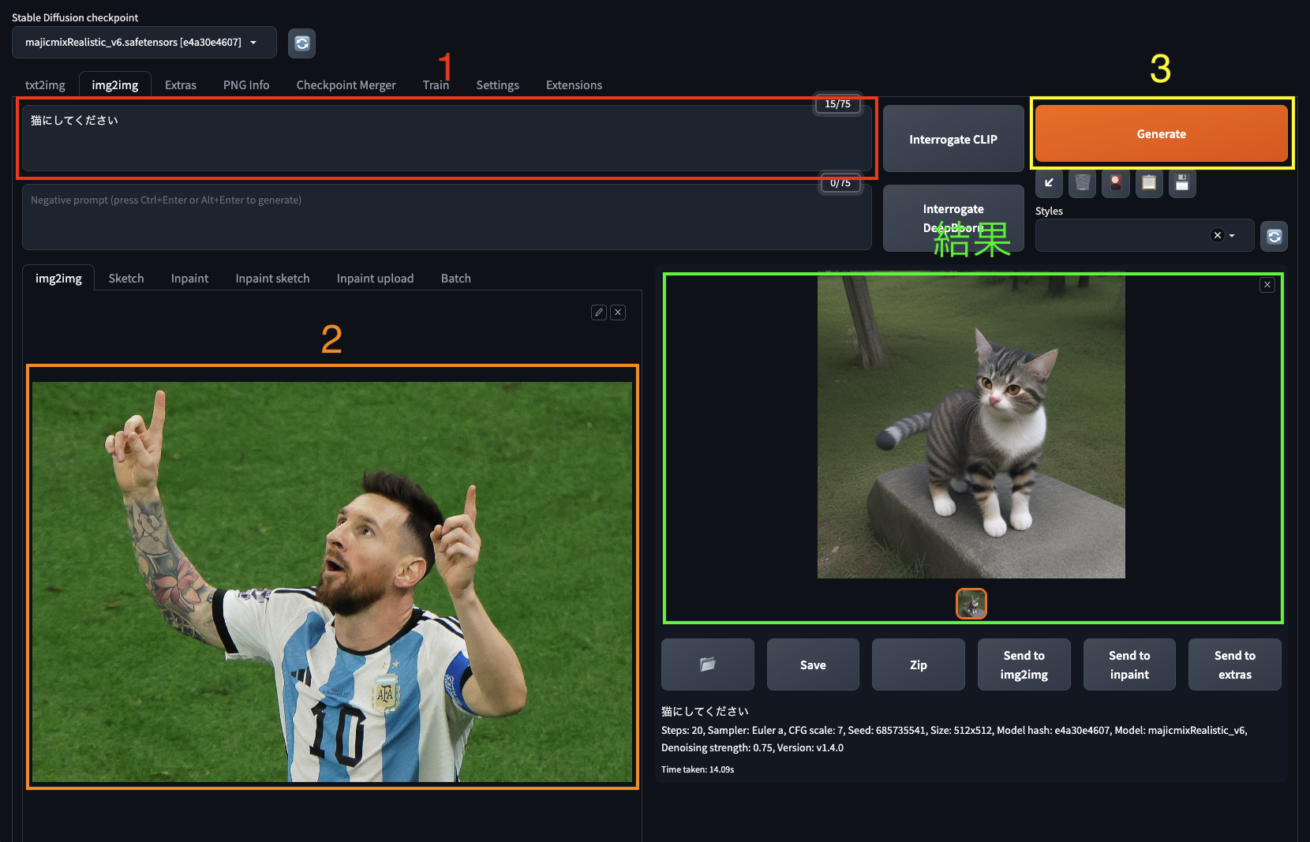
「猫にしてください」 とプロンプトを入力すると、次の結果になりました。
4.アウトプットを微修正する方法
Stable Diffusionはデフォルトの設定だとランダムな生成をおこなっているため、同じテキストをプロンプトとして入力しても生成される画像が異なります。
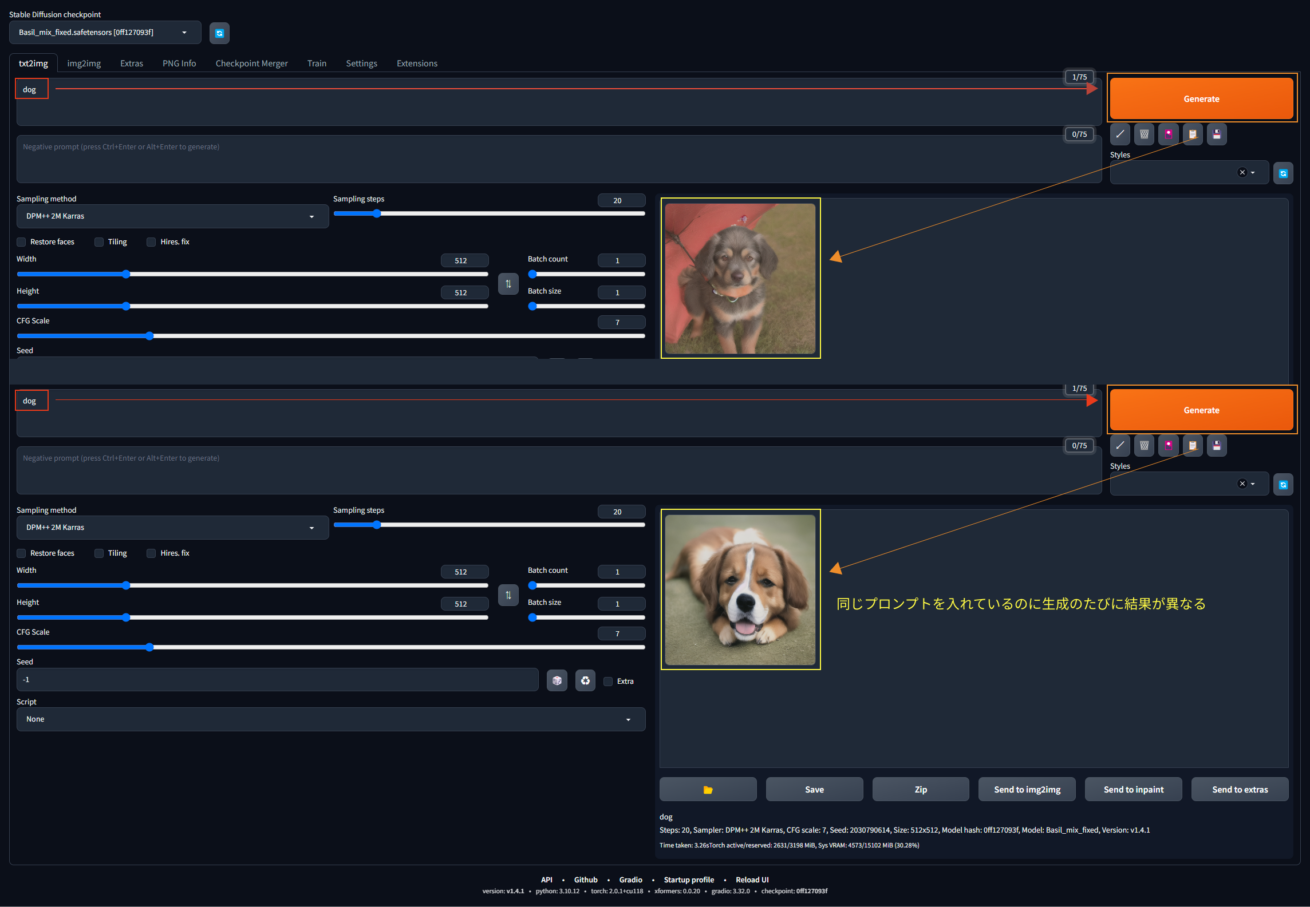
この仕様は実用面で少し不便です。画像を微修正したり、近しい構図の画像を複数作成して比較検討したりすることができません。
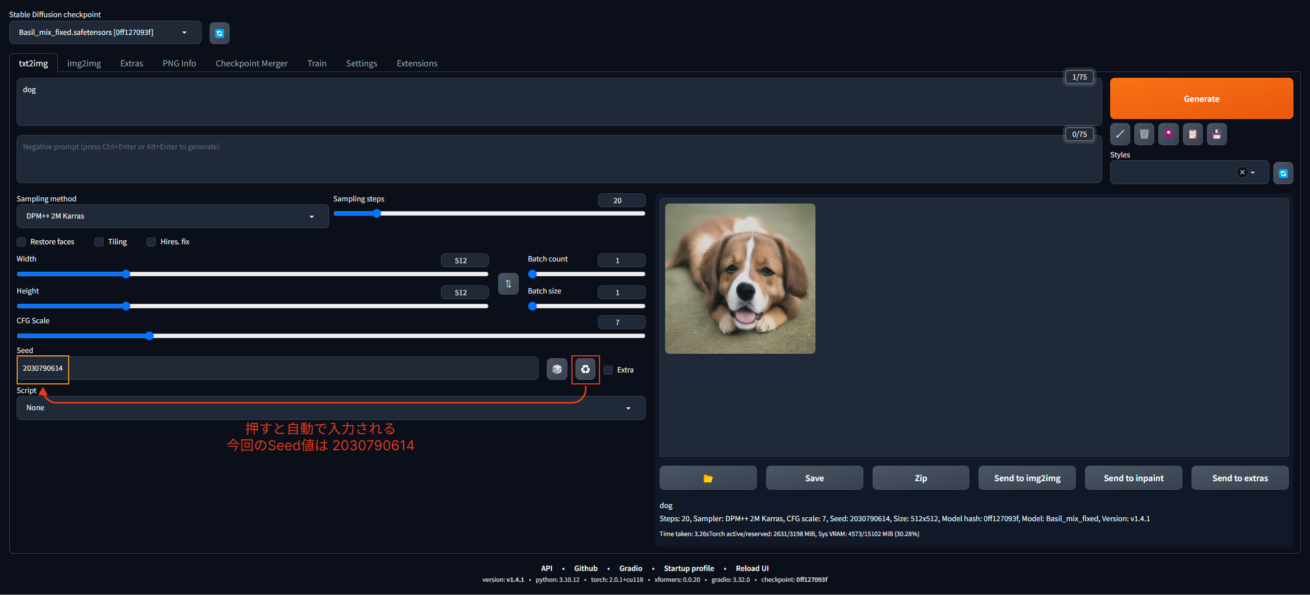
その場合は、「Seed値」を使ってアウトプットのばらつき減らしましょう。
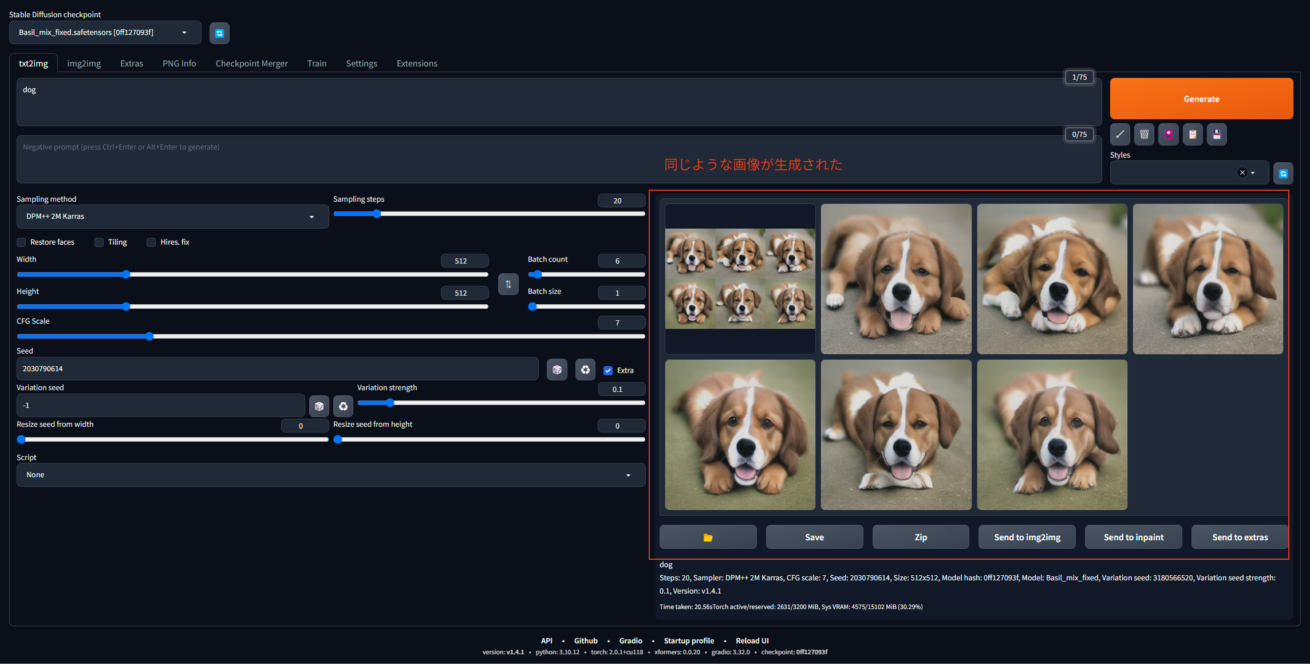
Seed値とはStable Diffusionがどのように計算したかの値です。同じSeed値を入力すれば、誰でも同じ犬の画像を再生成することができます。今回の画像のSeed値は 2030790614。これは数字入力欄の二個右の3つの矢印マークを押すと自動で表示されます。
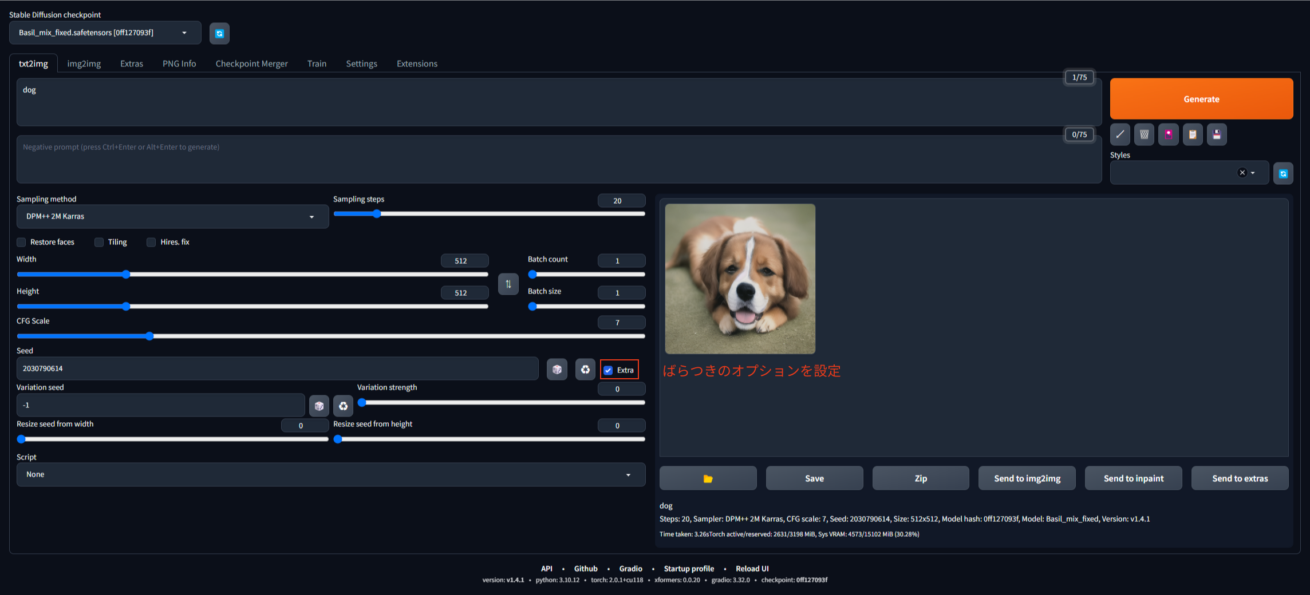
赤枠の箇所にチェックを入れて、ばらつきのオプションを設定していきましょう。
「Variation Strength」を0.1にしました。この値が大きくなればなるほど、生成された画像はばらつきます。
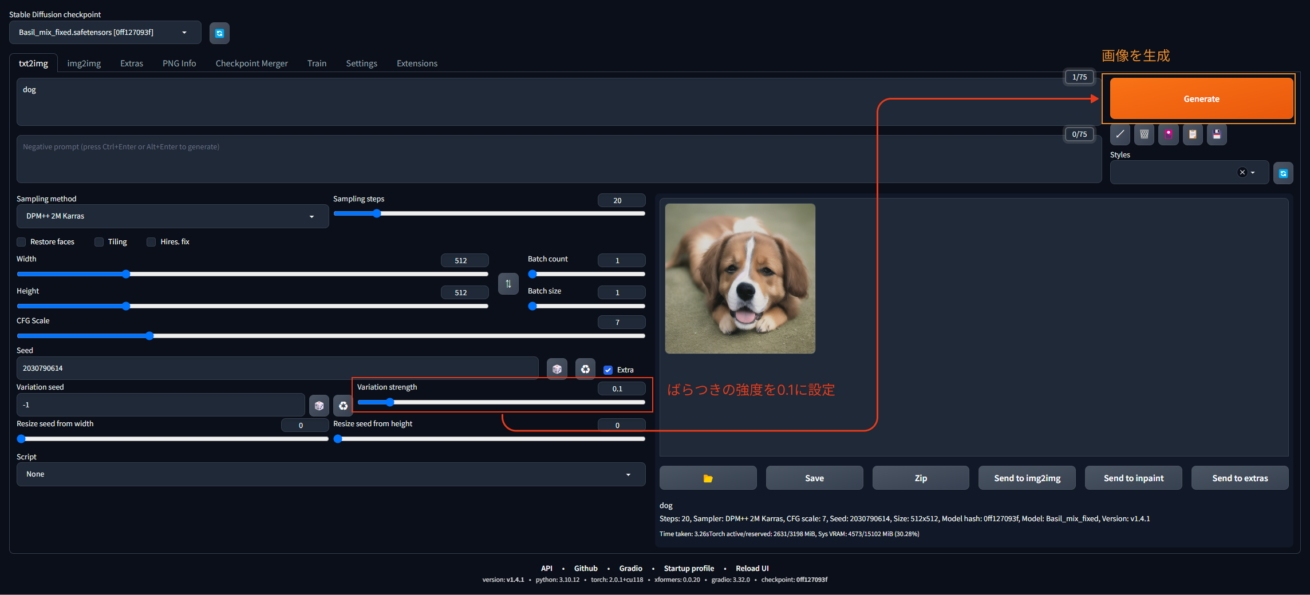
0.1の状態で生成すると、オリジナルとそっくりの画像を作ることができました。
もしまたランダムに生成したければ、Seed値を-1に設定してください。そうするとまたいろんな画像が出てくるようになります。
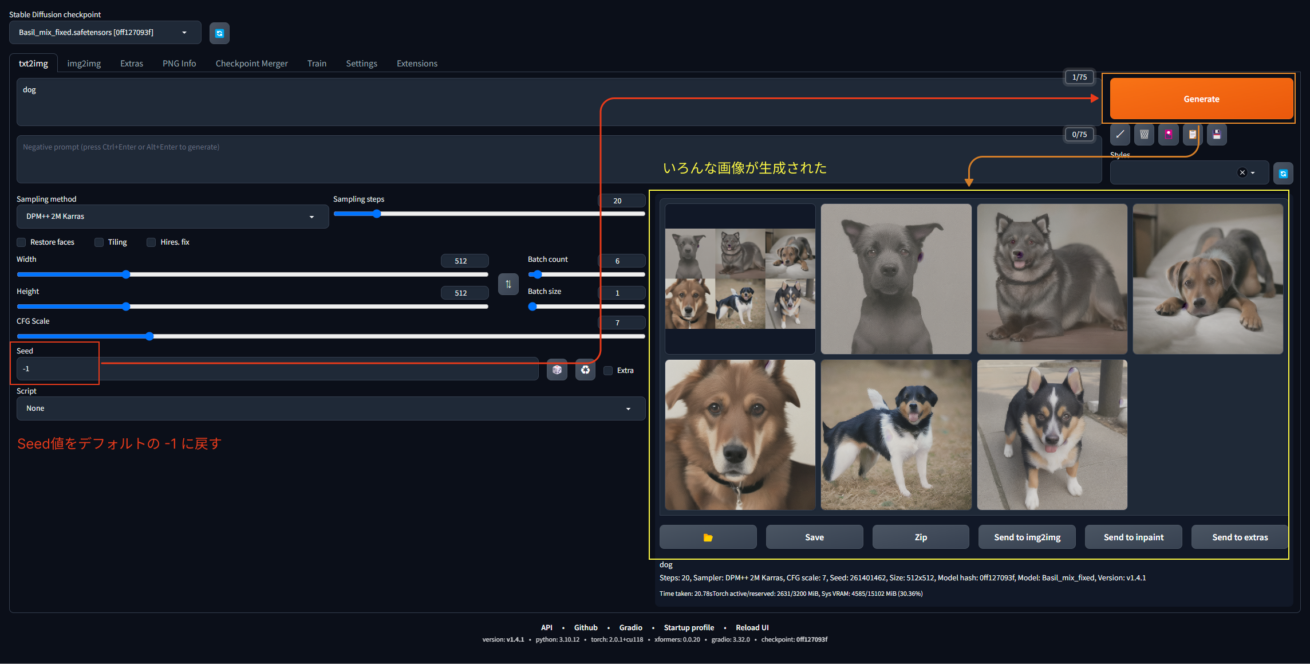
Seed値を調整しばらつきを増やしたり減らしたりすることで、理想のイメージに近づけていきましょう。
まとめ
「AUTOMATIC1111 Stable Diffusion WebUI」があれば、Stable Diffusionが簡単に使えるようになります。ノイズレベルや生成画像のサイズの変更など、設定パネルでさまざまな調整も可能です。
また、テキストベースの「txt2img」を使えば、より創造的な画像を生成できます。しかし、生成される画像はつねにプロンプトに一致するとは限りません。一方で画像ベースの「img2img」は、元の画像に近いイメージを生成できますが、より現実的な仕上がりになるでしょう。ご自身の用途によって、ぜひ使い分けてみてください。
この記事が参考になれば幸いです。
また、LIGでは生成AIコンサルティング事業をおこなっています。ぜひ気軽にご相談ください。
最新情報をメルマガでお届けします!
LIGブログではAIやアプリ・システム開発など、テクノロジーに関するお役立ち記事をお届けするメルマガを配信しています。
- <お届けするテーマ>
-
- 開発プロジェクトを円滑に進めるためのTIPS
- エンジニアの生産性が上がった取り組み事例
- 現場メンバーが生成AIを使ってみた
- 開発ツールの使い方や開発事例の解説
- AIをテーマにしたセミナーの案内
- 最新のAI関連ニュースまとめ など
「AIに関する最新情報を集めたい!」「開発ツールの解説や現場の取り組みを知りたい!」とお考えの方は、ぜひお気軽に無料のメルマガをご購読くださいませ。











