
こんにちは。バックエンドエンジニアのまさくにです。
あんまり他の会社だと発生しない悩みだと思うのですが、弊社はゴリゴリのあだ名文化が浸透していまして、社員の本名がわからない、本名がわからないと内線番号もわからない、というような意味不明な問題が多発しています。
人事労務的にはあだ名でお役所仕事が通るわけないので本名で管理しなければならない、でもビジネスネームとしてあだ名が存在するので対外的にはあだ名を使わなければならない、というジレンマがその原因です。
じゃああだ名文化を撤廃すればいいじゃんって話もあるのですが、LIGはあだ名でなければならないというわけではありません。実際、僕は本名の「まさくに」で通しています。「呼びやすく、呼ばれやすく、仲良くなりやすい」という考えがベースにあって、本名がよければそれでもいいし、あだ名の方がよければそれでもいい、一つのカルチャーなので大事にしたいところです。
で、作りました。
SlackでLIGの社員を検索できるbotです。あだ名や本名から、その社員のプロフィールを持ってくるようにしました。名前は人間関係の始まり、LIGもそうですが、そろそろ社員が増えてきて知らない人多いなぁって思いはじめた他社様でもご検討されてはいかがでしょうか。
初めに言っとくとすげぇ面倒なのでおすすめしません。
こうしたいと思う
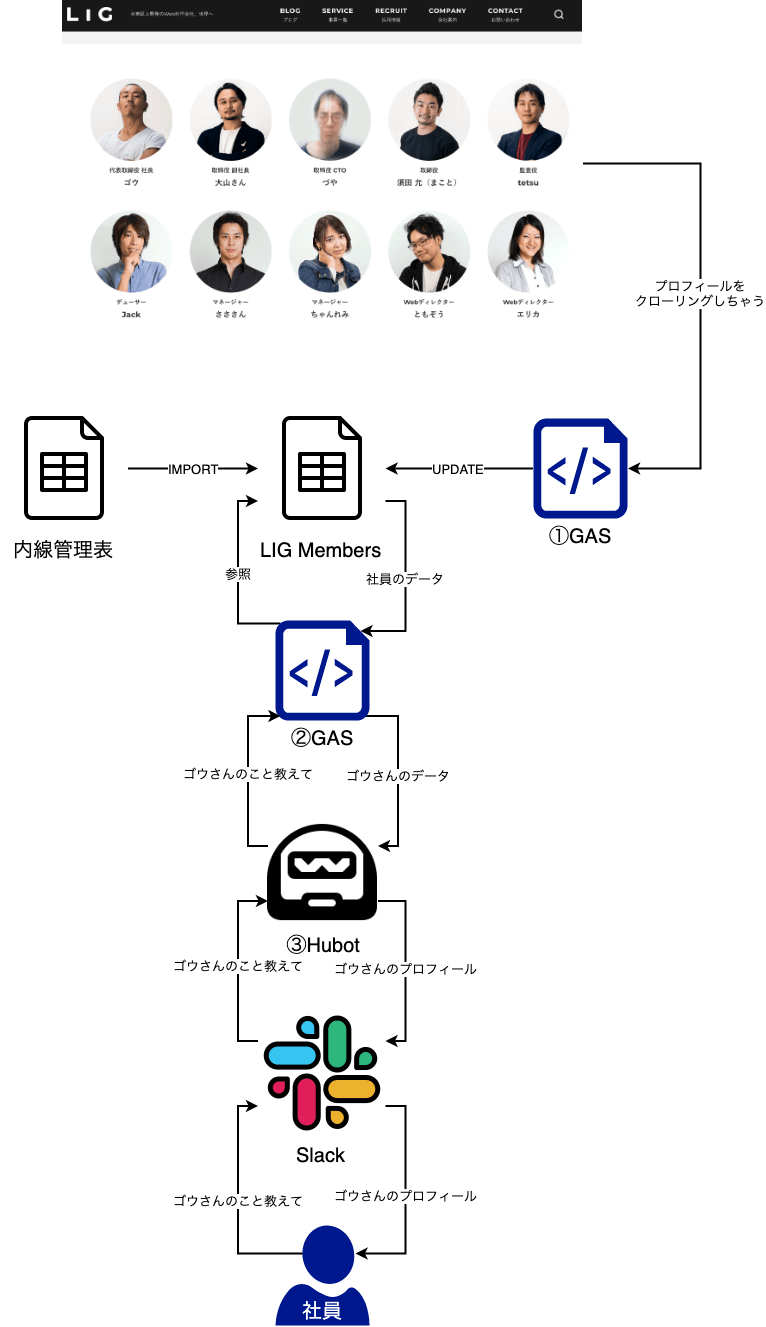
上の図で番号振ってあるところは実装が必要です。
実装はこうなった
事前準備:メンバー一覧のスプレッドシートを作っておく
この社員一覧をもとにしてSlackへ結果を投げます。下記のような情報が必要なので、カラムを用意しました。以降はこの列にしたがって説明しますが、一例ですので必要な情報は会社ごとに異なると思います。
| No. | このシートで使う一意のシステム値にします。 |
|---|---|
| 有効 | チェックボックスで、この社員が有効か否かを示します。 |
| 社員番号 | 社員番号ですが、すべての社員に振られているとは限りません。 |
| 姓名/日本語 | 社員の姓名。 |
| 姓名/英語 | 社員の姓名の英語表記。セブ社員もいるので。 |
| あだ名/日本語 | 社員のあだ名。 |
| あだ名/英語 | 社員の英語でのあだ名。 |
| チーム | 社員が属しているチーム。 |
| ユニット | LIGでは職能ごとに「ユニット」があります。社員の職能です。僕だったら「バックエンド」となります。 |
| メールアドレス | 社員のメールアドレス。 |
| LIGブログID | LIGブログのユーザーIDです。ゴウさんならgosan。 |
| アプリ内線 | 社員が持っている内線番号。他のシートからIMPORTRANGE()とVLOOKUP()を使って引き当てています。 |
| アプリ直通 | 社員が持っている直通番号。 |
| LIGブログバナーURL | LIGブログに載っている社員のバナー画像のURLです。勝手にクロールしてきます。 |
| LIGブログ記事数 | LIGブログに載っている社員の記事数です。勝手にクロールしてきます。 |
| LIGブログ自己紹介 | LIGブログに載っている社員の自己紹介です。勝手にクロールしてきます。 |
| 検索文字列更新日時 | システムで利用します。 |
| クロール日時 | システムで利用します。 |
| エラーメッセージ | 一連のフローでエラーがあった場合、エラーメッセージが書かれます。 |
上記の項目の中で、手動で埋めとかなければならない情報、クローリングの情報の鍵となる情報を記載しておきます。今回でいえば下記の情報をあらかじめ入力する必要がありました。
- 社員番号
- 姓名/日本語
- 姓名/英語
- あだ名/日本語
- あだ名/英語
- チーム
- ユニット
- メールアドレス
- LIGブログID
①GASでLIG Blogをクローリングする
LIG Blogをクローリングするのはこれで何度目になるでしょう。いま思えばさまざまな言語、方法でLIG Blogのクローリングを行ってきました。今回はGAS、ライブラリを使います。
下記を利用させていただきました。
Parser
https://www.kutil.org/2016/01/easy-data-scrapping-with-google-apps.html
タグの始まりと終わりを指定して、中の文字列を持ってくるというシンプルなライブラリですが、セレクタで持ってくるようなスクレイピングのライブラリと比べると、少し癖があります。GASを開いて、「リソース>ライブラリ」からこのParserの識別子(上記ページ参照)を入力すると、Parserを使えるようになります。
LIGメンバーページは全く更新がないページなので、10日に一回の更新で、一回に10人ずつ更新するようにすれば十分です。下記のようなコードになります。
var MAX_WRITTEN_LINE_CNT = 10
var spreadsheet = SpreadsheetApp.openById(PropertiesService.getScriptProperties().getProperty('SPREADSHEET_ID'));
function crawl(query) {
var membersSheet = spreadsheet.getSheetByName('Members')
var writtenLineCount = 0
var rows = membersSheet.getDataRange().getValues()
for (rowNum = 1; rowNum < rows.length; rowNum++) {
var row = rows[rowNum]
// 書き込み上限を超えていたら終了
if (writtenLineCount >= MAX_WRITTEN_LINE_CNT) break
// 有効でなければクロール対象としない
if (row[1] != true) continue
// LIGブログIDが指定されてなければクロール対象としない
if (!row[10]) continue
// 10日経っていなければクロール対象としない
var now = new Date()
var updatedAt = new Date(1970, 0, 1, 0, 0, 0)
if (row[17]) {
updatedAt = new Date(row[17])
}
if (now.getTime() - updatedAt.getTime() <= 86400 * 10) {
continue
}
try {
// クロール
var html = UrlFetchApp.fetch('https://liginc.co.jp/member/member_detail?user=' + row[10]).getContentText()
// バナー
var parser = Parser.data(html)
var tmp = parser.from('<div class="author-detail-visual">').to('</div>').build().trim()
var bannerUrl = Parser.data(tmp).from('src="').to('"').build().trim()
membersSheet.getRange(rowNum + 1, 14).setValue(bannerUrl)
parser = Parser.data(html)
var blogCnt = parser.from('<span class="author-detail-count-num">').to('</span>').build().trim()
membersSheet.getRange(rowNum + 1, 15).setValue(blogCnt)
parser = Parser.data(html)
var tmp = parser.from('<div class="author-detail-description">').to('</div>').build().trim()
var profile = tmp.replace(/\n/g, '').trim()
membersSheet.getRange(rowNum + 1, 16).setValue(profile)
membersSheet.getRange(rowNum + 1, 19).clearContent()
} catch (e) {
var message = e.message.replace(/\n/g, '').trim()
membersSheet.getRange(rowNum + 1, 19).setValue(message)
}
membersSheet.getRange(rowNum + 1, 18).setValue(now)
writtenLineCount++
}
}2行目の PropertiesService.getScriptProperties().getProperty(‘SPREADSHEET_ID’) はGASのスクリプトのプロパティで設定できます。SPREADSHEET_IDに事前準備で作ったドキュメントのIDを入力しておいてください。こうして書いておくと、GASとトークンを別に管理できて便利ですね。
このスクリプトを一日に一回くらい、時間のトリガで自動起動させておいてください。このスクリプトが実行されると、スプレッドシート上の、LIGブログバナーURL、LIGブログ記事数、LIGブログ自己紹介が自動で取得されます。「これ手で書けばクローリングする必要なくない?」って思われた方、正解です。GASでクローリングしてみたかったので。
②GASでHubotのリクエストに答える
Slackからのリクエストがあったときに、社員の情報としてgrepするために全文検索っぽい仕組みを実装します。検索に必要なカラムをコンカチし、別のシート(SearchTargetsシート)に書き込んでおきます。
var spreadsheet = SpreadsheetApp.openById(PropertiesService.getScriptProperties().getProperty('SPREADSHEET_ID'));
var searchTargetId = [3, 4, 5, 6, 15]
function makeSearchTargets() {
var membersSheet = spreadsheet.getSheetByName('Members')
var searchTargetsSheet = spreadsheet.getSheetByName('SearchTargets')
var rows = membersSheet.getDataRange().getValues()
for (rowNum = 1; rowNum < rows.length; rowNum++) {
var row = rows[rowNum]
// 有効でなければ検索対象としない
if (row[1] != true) continue
// 2日経っていなければ検索対象としない
var now = new Date()
var updatedAt = new Date(1970, 0, 1, 0, 0, 0)
if (row[15]) {
updatedAt = new Date(row[15])
}
if (now.getTime() - updatedAt.getTime() <= 86400 * 2) {
continue
}
// 検索文字列
searchTarget = ''
for (colNum = 1; colNum < row.length; colNum++) {
// 走査対象ではないカラムは含めない
if (searchTargetId.indexOf(colNum) === -1) {
continue
}
searchTarget = searchTarget + ' ' + row[colNum]
}
if (!searchTarget) {
continue
}
searchTarget = searchTarget.replace(/\n/g, ' ').trim()
searchTargetsSheet.getRange(rowNum, 1).setValue(row[0]);
searchTargetsSheet.getRange(rowNum, 2).setValue(searchTarget);
membersSheet.getRange(rowNum + 1, 17).setValue(now);
}
}上記のコードで検索対象をSearchTargetsシートへ作り込んでおきます。次にHubotからリクエストを受けるGASをWeb APIとして作ります。とてもシンプルで衝撃を受けたため、下記の記事を参考にさせていただきました。
Google SpreadSheet のデータを JSON 形式で取得する Web API をサクッと作る
https://qiita.com/takatama/items/7aa1097aac453fff1d53
var MAX_ITEM_NUM = 10
var spreadsheet = SpreadsheetApp.openById(PropertiesService.getScriptProperties().getProperty('SPREADSHEET_ID'));
function getIds(query) {
var searchTargetsSheet = spreadsheet.getSheetByName('SearchTargets')
var rows = searchTargetsSheet.getDataRange().getValues()
return rows.filter(function(row) {
if (!query) return true
return row.join(' ').toLowerCase().indexOf(query.toLowerCase()) !== -1
}).map(function(row) {
return row[0]
})
}
function doGet(e) {
// idが一致するメンバーを抜きだす
var targetIds = getIds(e.parameter.q)
if (!targetIds) {
return ContentService.createTextOutput(JSON.stringify({}, null, 2))
.setMimeType(ContentService.MimeType.JSON)
}
// 対象データを削る
targetIds.slice(0, MAX_ITEM_NUM)
var membersSheet = spreadsheet.getSheetByName('Members')
var rows = membersSheet.getDataRange().getValues()
var keys = rows.splice(0, 1)[0];
var data = rows.filter(function (row) {
return (targetIds.indexOf(row[0]) >= 0)
}).map(function(row) {
var obj = {}
row.map(function(item, index) {
obj[String(keys[index])] = item
})
return obj
})
return ContentService.createTextOutput(JSON.stringify(data, null, 2))
.setMimeType(ContentService.MimeType.JSON)
}上記のスクリプトを書き込み、下記のように「ウェブアプリケーションとして導入」しておきます。これで提示されたURLにGETを投げると、doGetの処理に入っていきます。
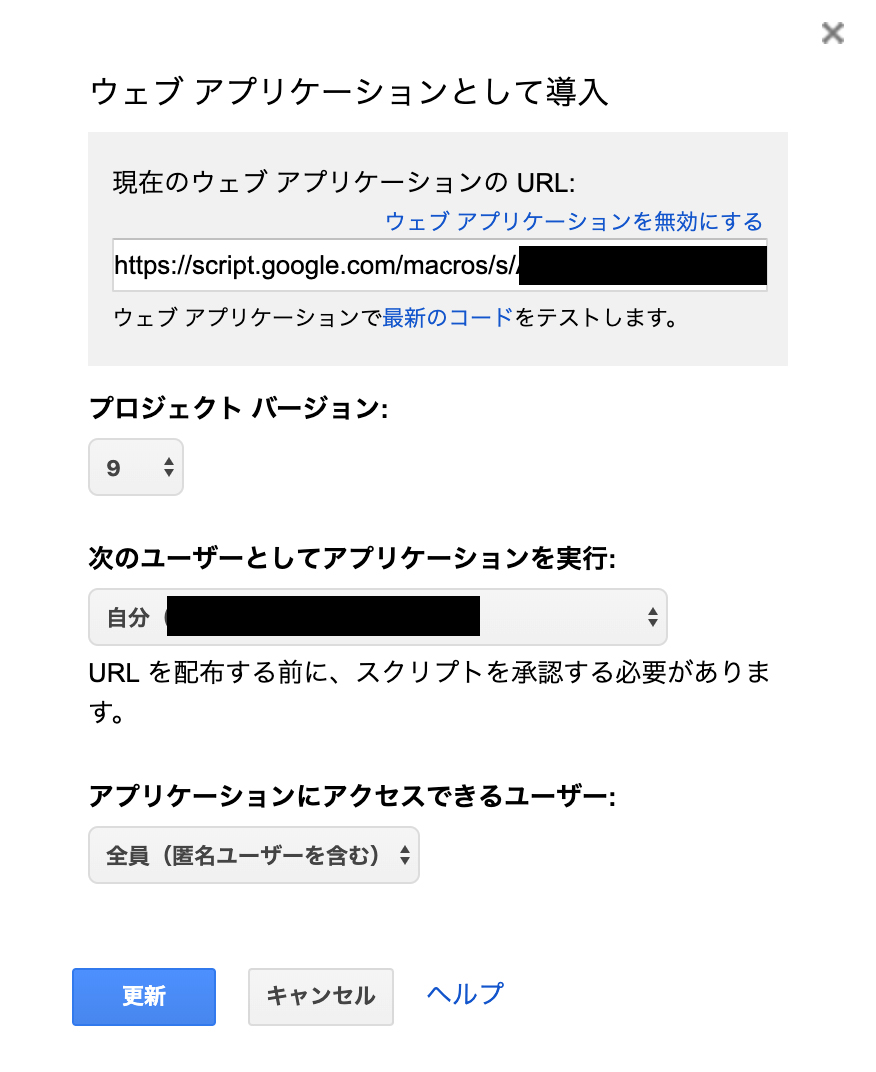
具体的には、ここで提示されたURLに対して、下記のように「ゴウ」などのパラメタを持たせると、ゴウさんのデータがJSONで帰ってくるようになります。
https://script.google.com/macros/s/XXXXXXXXXXXXXXXXXXXXXXXXXX/exec?q=ゴウ
このJsonをHubotで受け取って返すわけですね。これが本記事の中で一番便利なところだと思うのですが、皆さん、まだ興味を持たれていますでしょうか。
③HubotでSlackからのリクエストに答える
Hubotのscriptsディレクトリ配下にmember.coffeeを設置し、下記のようにスクリプトを書きます。
url = require 'url'
path = require 'path'
cheerio = require 'cheerio'
request = require 'request'
module.exports = (robot) ->
robot.respond /\s+member\s+list/i, (msg) ->
msg.send process.env.LIG_MEMBER_SPREADSHEET
robot.respond /\s+member\s+(.*)/i, (msg) ->
text = msg.match[1]
encodedText = encodeURIComponent(text)
url = process.env.LIG_MEMBER_URL + "?q=" + encodedText
try
profiles = []
request.get url: url, (error, response, body) ->
members = JSON.parse body
for idx, member of members
profile = ''
name = []
if (member['姓名/日本語'])
name.push(member['姓名/日本語'])
if (member['姓名/英語'])
name.push(member['姓名/英語'])
profile += "*" + name.join(' / ') + "*\n"
nickname = []
if (member['あだ名/日本語'])
nickname.push(member['あだ名/日本語'])
if (member['あだ名/英語'])
nickname.push(member['あだ名/英語'])
if (nickname.length)
profile += 'ニックネーム: ' + nickname.join(' / ') + "\n"
attributes = ['社員番号', 'チーム', 'ユニット', 'メールアドレス', 'アプリ内線', 'アプリ直通', 'LIGブログ記事数']
for attr in attributes
if (member[attr])
profile += attr + ': ' + member[attr] + "\n"
if (member['LIGブログ自己紹介'])
profile += "LIGブログ自己紹介:\n```" + member['LIGブログ自己紹介'] + "```\n"
if (member['LIGブログバナーURL'])
profile += member['LIGブログバナーURL'] + "\n"
profiles.push(profile)
msg.send profiles.join("---\n")
catch error
msg.send 'ERROR: Request failed.'ここで process.env.LIG_MEMBER_URL は先ほどGASから取得したウェブアプリケーションのURLを .env で設定しておきます。
小さな改善だが、大きな一歩
結果はこうなります。いまのLIGのHubotは紆余曲折あって @ligsh って名前なので、ligshが入っているチャンネルで下記のように打つと、ゴウさんのプロフィールを引けるようになりました。
@ligsh member ゴウ
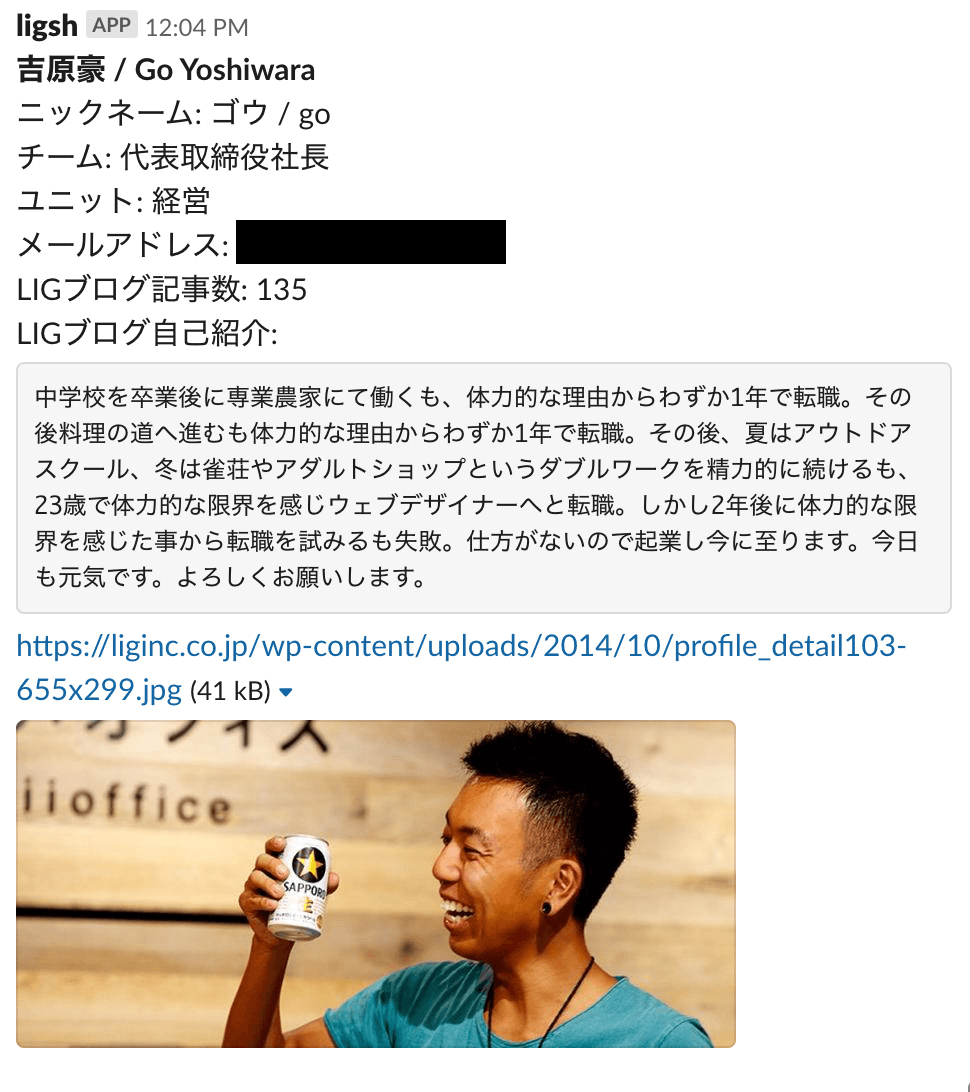
個人的にはこのように写真がプレビューされるのが、この仕組みの中で最も優れている(この機能とSlackの親和性が高かった)部分だと思っているのですが、他社員からは「自分のイキっている写真がSlackで晒されるのは恥ずかしい」という声が多数あがりました。
このため、プロフィールを調べるときは @ligsh へのDMで個人的に調べるとよいとされ、パブリックなチャンネルでこの機能を使う人は皆無になりました。みんなその写真、世界に公開してることわかってんのかな。
こういう社内のインフラで、もっとも根底にあるボトルネックを解消していくと広域に良い影響がでていくので、すごい面倒な小さな一歩ですが、一歩ずつ改善を繰り返したいと思います。でも、そもそもこの仕組みがいらない方法はいろいろあると思いますので、この方法はあまりおすすめしません。まだみなさん、読まれていますでしょうか。バックエンドエンジニアのまさくにでした。
LIGはWebサイト制作を支援しています。ご興味のある方は事業ぺージをぜひご覧ください。









