
Technology部のJoshです。
AIや機械学習の技術は日々進化しています。なかでも、LangChainの開発元がリリースした大規模言語モデル(LLM)アプリケーション開発を支援するプラットフォーム「LangSmith」は注目すべき存在です。
この記事ではLangSmithの基本的な機能や、データセットの設定からLLM出力の評価まで、サンプルとともにご紹介します。初心者の方から経験豊富な開発者まで、LLMプロジェクトにLangSmithを活用するためにこの記事がお役立てできれば幸いです。
LangSmithとは
LangSmithとは、LLMアプリ開発フレームワーク「LangChain」の開発元がリリースした、LLMアプリ開発支援サービスです。LangSmithを使えば、LLMアプリケーションデータ(チェーン会話、プロンプトなど)の保存、編集、再実行、管理が可能となります。現在はOpenAIモデルのみサポートしていますが、開発者や研究者にとって有用なツールといえるでしょう。
LangSmithの主な用途としては、LLMの実行ログ収集やデータセット作成、モデル評価などです。テキストだけではイメージしにくいかと思いますので、ここからは例を見ながら使い方を解説します。
LangSmithの初期設定
LangSmithを使用する前には、環境を正しく設定することが重要です。LangSmithだけでなく、LangChainからのさまざまなコンポーネントなど、必要なモジュールをインポートしましょう。
LangSmithのインストール手順は公式ドキュメントに詳しく記載されています。以下のように、LangSmithプロジェクトをコードに組み込む方法を示すPythonとTypeScriptの例も記載されているので、ご参考になさってください。なお、一意なプロジェクト識別子を使用することで、複数のアプリケーションのログを一つのLangSmithプロジェクトに記録することも可能です。
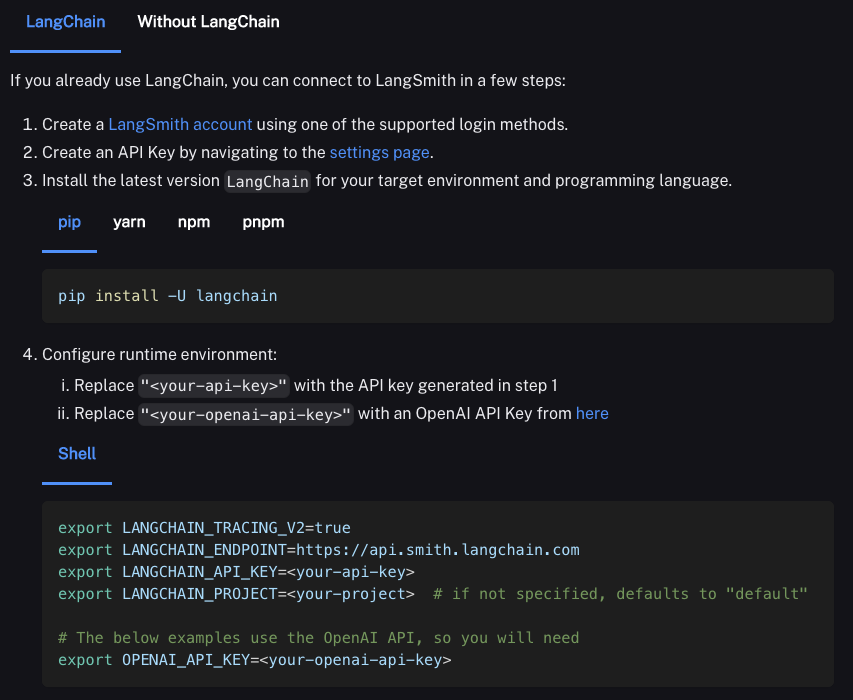
shell
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project>
export OPENAI_API_KEY=<your-openai-api-key>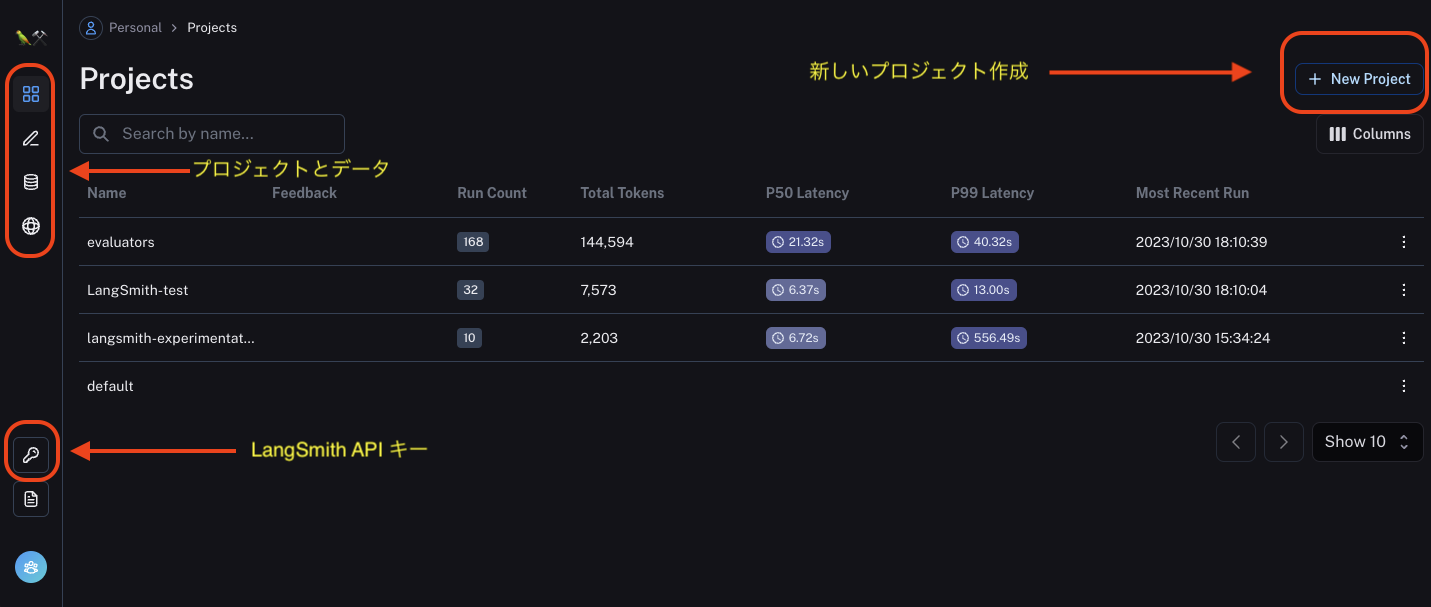
こちらがLangSmithの基本的なランディングページです。左側メニューから、APIキー管理、ドキュメントへのアクセス、ユーザー管理などの機能にアクセスできます。現在進行中のプロジェクトもすべてこのエリアに表示され、管理できます。
LLMとの対話とログの確認方法
セットアップが完了すると、LangSmithクライアントと大規模言語モデル(LLM)との対話を開始できます。
LangChainコードのタグを使用して実行回数、レイテンシー(P50、P99)、アプリケーションコールごとのトークン使用量などのメトリクスを収集可能です。例として今回はChatOpenAIモデルを使用して、クエリに対する応答を取得する簡単なサンプルを作ってログを確認してみます。
プロジェクト作成
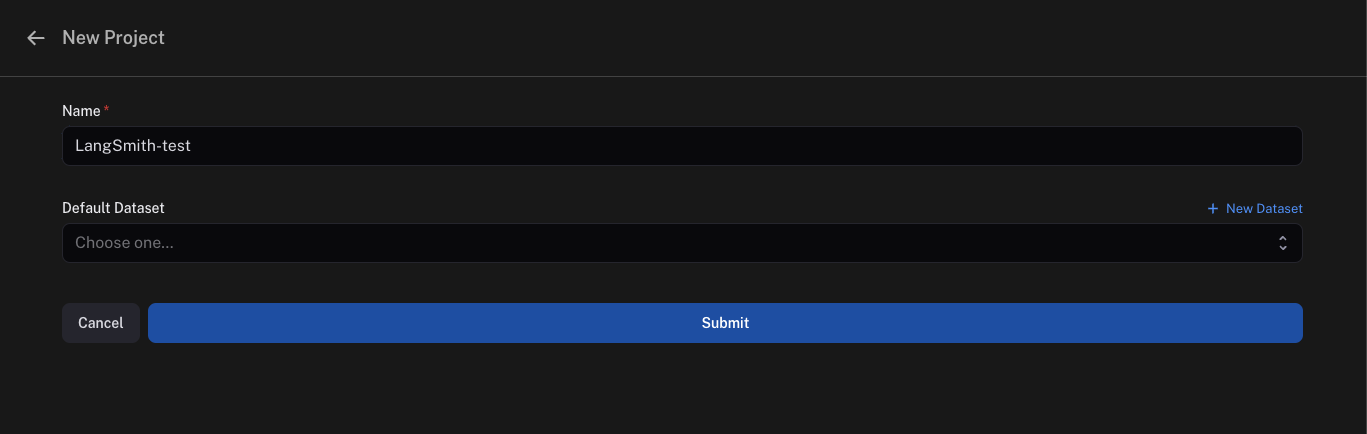
LangSmith UIで、「LangSmith-test」という名前のプロジェクトを作成します。
環境設定とインポート
OS、nest_asyncio、LangSmithのClient、Langchain.chat_modelsのChatOpenAIなど、必要なモジュールをインポートします。Jupyterノートブックや類似の環境内で非同期IOを有効にするためにnest_asyncioを適用します。
shell
pip install nest_asyncio langsmith langchainpython
# --------------------------------------------------------------
# モジュールのインポート
# --------------------------------------------------------------
import os
import nest_asyncio
from langsmith import Client
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.smith import RunEvalConfig, run_on_dataset
nest_asyncio.apply()環境変数とAPIキー
LangSmith API、トレーシング、エンドポイント、プロジェクトの詳細に関する環境変数と、GPTモデルとの対話に使用するOpenAI APIキーを設定します。
python
os.environ["LANGCHAIN_API_KEY"] = "LangSmith API Key"
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_PROJECT"] = "LangSmith-test"
os.environ['OPENAI_API_KEY'] = "openAI API Key"LangSmithクライアントの初期化と実行
LangSmithクライアントとChatOpenAIモデルを初期化します。すべて正しく設定されていることを確認するためにテスト予測を行います。
python
client = Client()
llm = ChatOpenAI()
llm.predict("What can you do?")テストで問題がなければ、LLMを実行しましょう。
shell
python3 filename.py結果を確認する
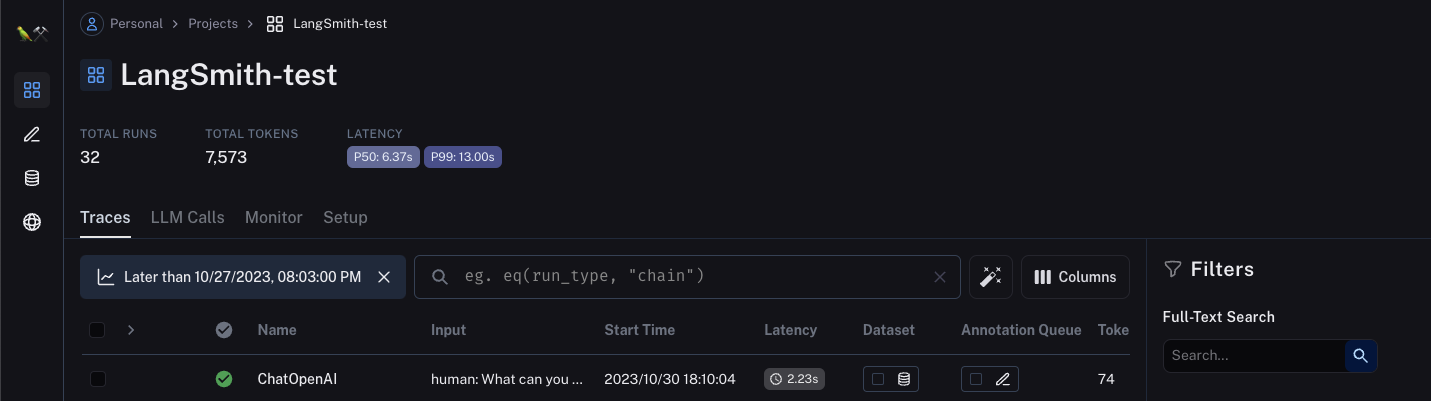
実行した結果はLangSmith内ですぐに確認できます。Pythonコードから参照された「Langsmith-test」というプロジェクトを開くと、実行ログが表示されます。
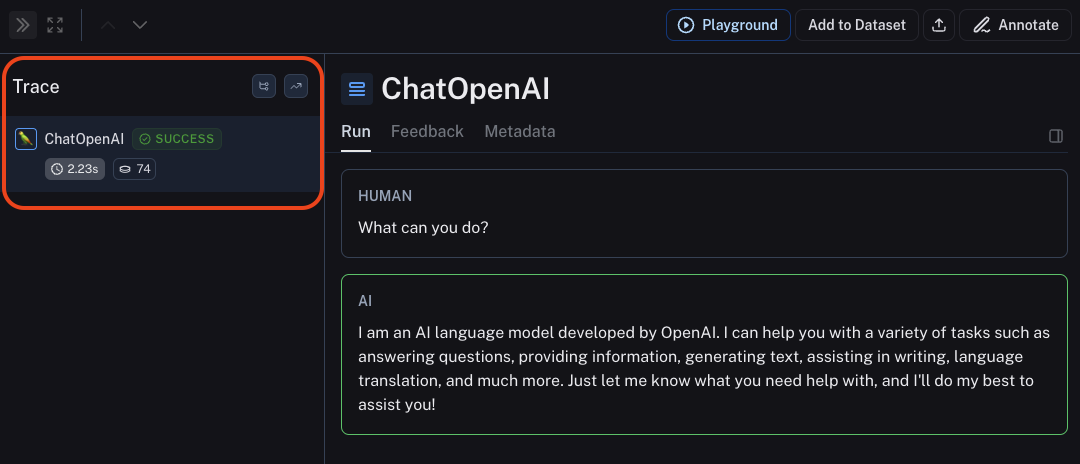
トレースウィンドウにはレイテンシー、使用されたLLM、およびトークンが表示されます。この実行ログデータは共有したり、データセットに保存したり、自身の操作により評価したりできます。
手動で細かく調整をおこなうためには画面上部の「プレイグラウンド」を使用してください。2023年12月現在、プレイグラウンドはOpenAI専用の機能です。プレイグラウンドではプロンプトの編集が可能で、アウトプットや各種パラメーターの変化を確認しながら調整をおこなえます。
評価用データセットを作成する
データセットの作成
続いて、データセットの例として歴史上の人物間の討論などを定義します。LangSmithで新しいデータセット「Historical Debate dataset sample」を作成します。
python
# --------------------------------------------------------------
# 評価クイックスタート
# 1. データセットの作成(入力のみ、出力なし)
# --------------------------------------------------------------
example_inputs = [
"a debate between Albert Einstein and Isaac Newton on the nature of gravity make it just short",
"a debate between Cleopatra and Queen Elizabeth I on leadership make it just short",
"a debate between Steve Jobs and Thomas Edison on innovation make it just short",
"a debate between Plato and Confucius on ethics make it just short",
]
dataset_name = "Historical Debate dataset sample"
# 入力をデータセットに保存することで、
# 共有された一連の例に対してチェーンとLLMを実行できます。
dataset = client.create_dataset(
dataset_name=dataset_name,
description="HistoricalDebate サンプルプロンプト。",
)
for input_prompt in example_inputs:
# 各例はユニークであり、入力が定義されている必要があります。
# 出力はオプションです
client.create_example(
inputs={"question": input_prompt},
outputs=None,
dataset_id=dataset.id,
)データセット評価設定
RunEvalConfigを使用して評価設定を定義します。下記のように、Harmfulness(有害性)、Misogyny(ミソジニー)、Accuracy(正確性)など、さまざまな評価基準を指定しましょう。
Python
# --------------------------------------------------------------
# 2. LLMを使用したデータセットの評価
# --------------------------------------------------------------
eval_config = RunEvalConfig(
evaluators=[
# 評価者を名前/列挙型で指定できます。
# この場合、デフォルトの基準は「役立ち度」です
"criteria",
# 評価者を設定することもできます
RunEvalConfig.Criteria("harmfulness"),
RunEvalConfig.Criteria("misogyny"),
RunEvalConfig.Criteria(
{
"Accuracy": "回答は理にかなっていて正確ですか? "
"そうであればYを、完全に架空であればNを返答してください。"
}
),
]評価の実行
指定された設定でデータセットを評価するためにrun_on_datasetを使用します。
Python
run_on_dataset(
client=client,
dataset_name=dataset_name,
llm_or_chain_factory=llm,
evaluation=eval_config,
)結果を確認する
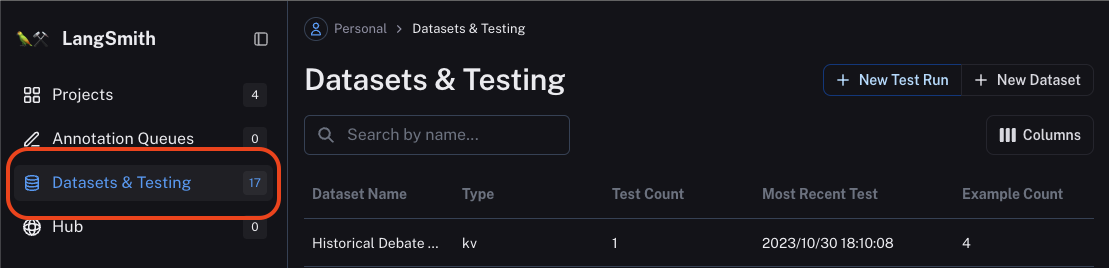
結果は「Datasets&Testing」のセクションから閲覧できます。
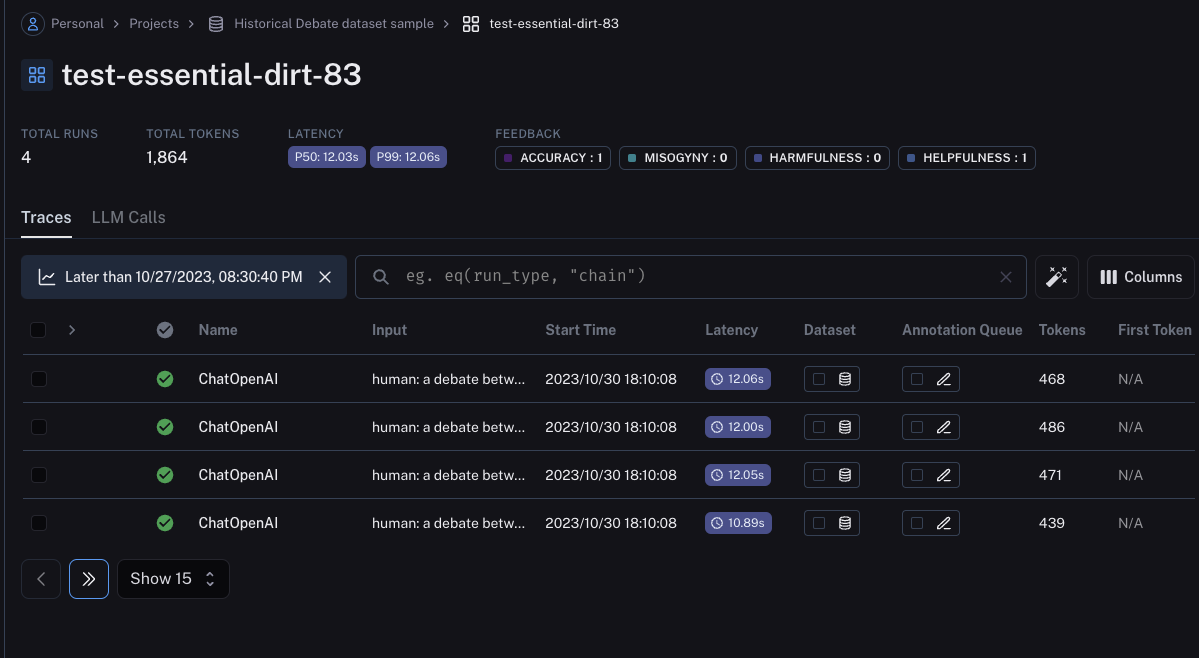
データセット名をクリックすると、詳細を観察できます。
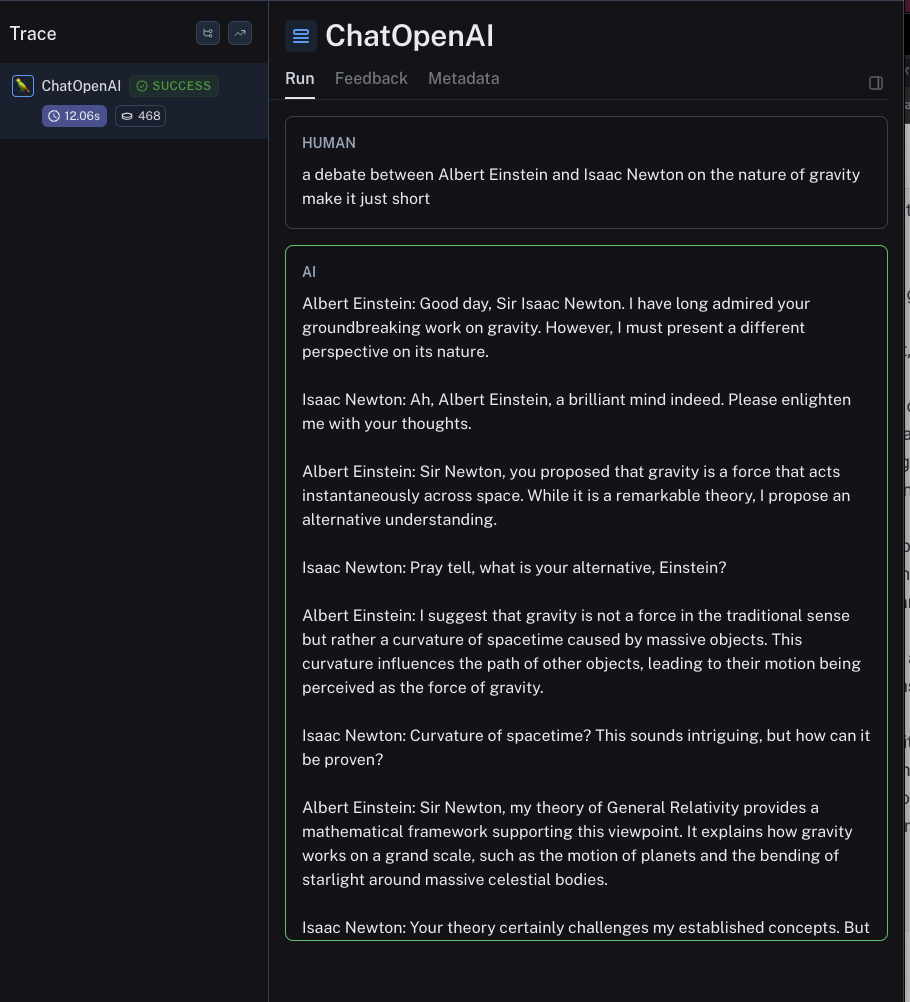
各データセットからはプロンプトメッセージの結果も表示できます。
まとめ

LangSmithの基本的な使い方を紹介しました。仕組みが少し複雑ですが、ログ収集やデータセットの作成、モデルの評価に至るまで、LLMアプリケーション開発の様々な側面を扱える便利なサービスです。
LLMアプリケーションの品質と信頼性を保証するためには、評価とモニタリングが非常に重要です。実運用におけるデバッグ、検証、評価をより効果的におこなうためにも、LangSmithを活用してみてはいかがでしょう。











