
「自社サイトの数値分析、もっと楽にできないかな〜」と思ったことがあるみなさんに朗報です。
AIとGA4などのツールを連携すれば、AIと会話するだけで簡単にサイト分析ができるようになります!
特におすすめなのが、BigQuery MCPとClaudeの連携です。たとえば「直近1週間で◯◯事業に問い合わせをしたユーザーのLPと、問い合わせ完了までの行動経路を分析してほしい」と指示すると、こんな感じでまとめて出してくれるようになります。
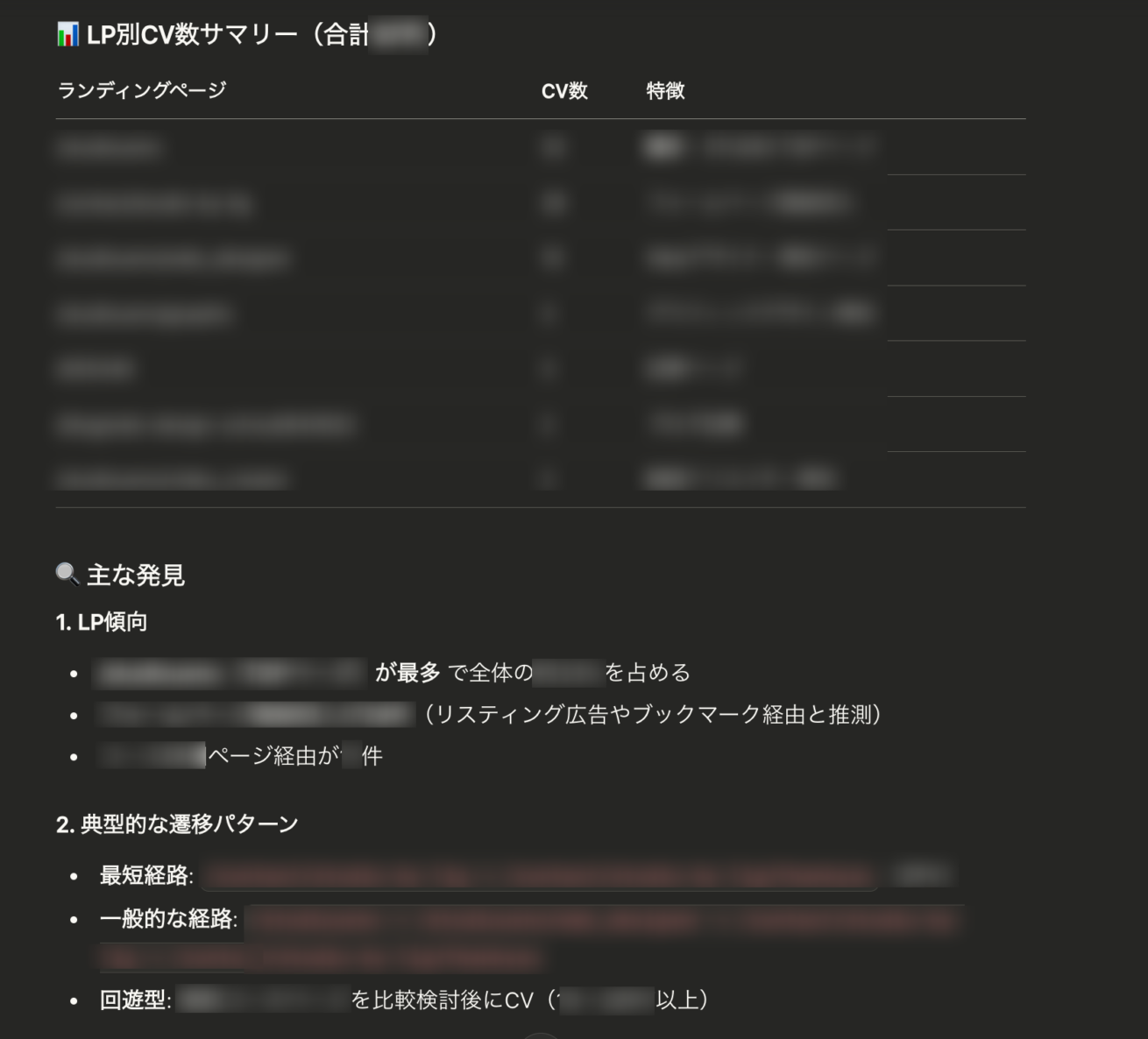
ご覧の通り、数値の洗い出し〜状況分析まで一気に出してくれるだけでなく!
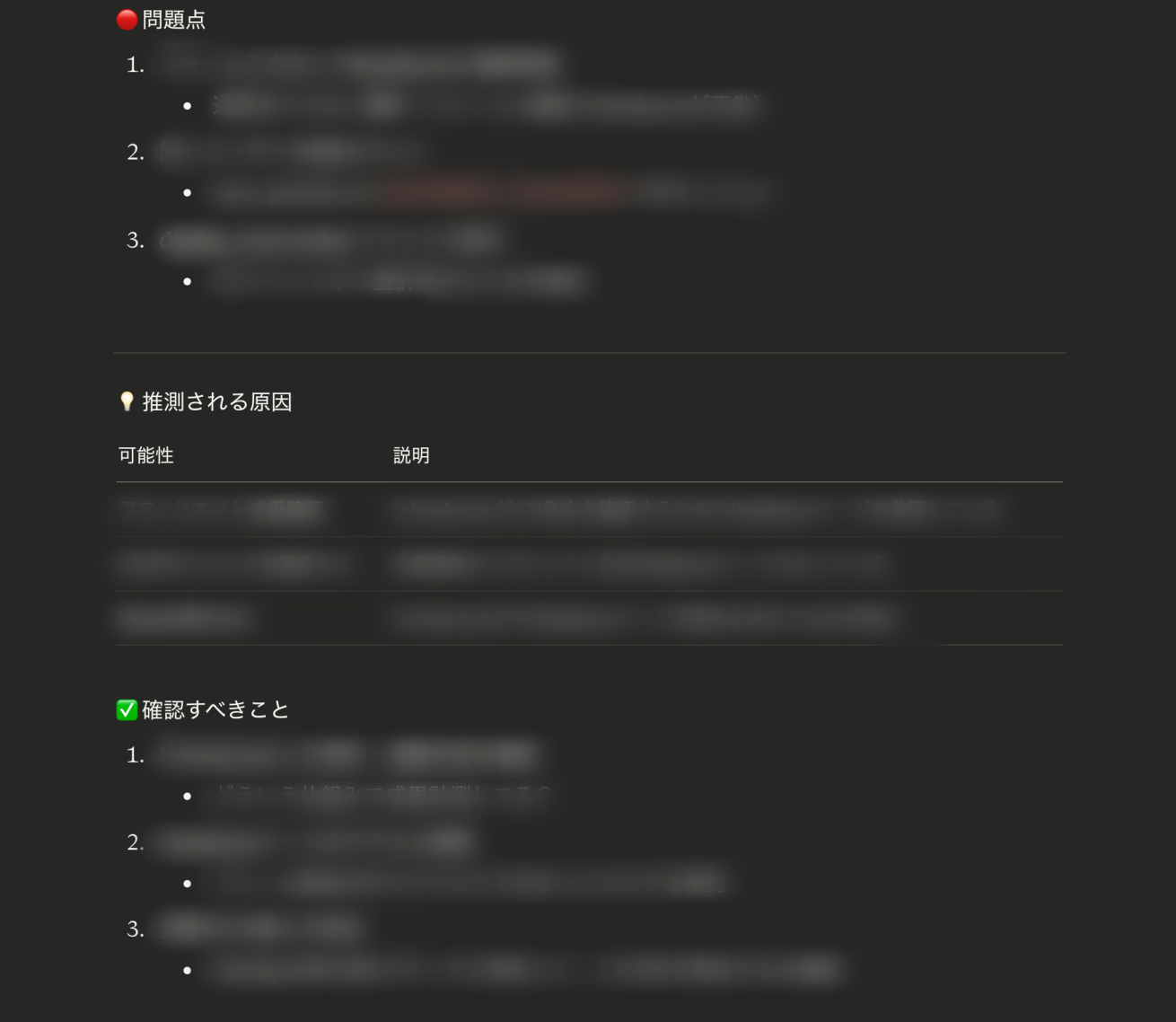
問題点や確認事項、改善案まで一気に提案してくれます!(リアルな内容なので中身を見せられずすみません……)
今回は非エンジニアの私でも簡単にできた、BigQuery MCP×Claudeのセットアップ方法と、実際の使用例をご紹介します!
そもそもBigQueryとかMCPって何?
- 💡ざっくり解説
- BigQuery:Google Cloudが提供しているクラウドデータウェアハウス(DWH)のこと。巨大なデータをSQLという言語で高速&柔軟に加工できるのが特徴で、GA4やSearch Consoleとも連携可能。
MCP(Model Context Protocol):AIアシスタントが外部のデータやツールに安全に接続するための仕組み。Claudeの開発企業でもあるAnthropic社が開発。
つまり、BigQuery MCPは、BigQueryをAIツールと安全に接続するための橋渡し役といえます。
実はGA4とClaudeを直接連携することも可能です。しかし、GA4の探索レポートで使えるような経路分析やセグメント比較などの高度な分析には制限があります。
一方、BigQueryにはGA4の生データがそのまま入っているので、冒頭でお見せした経路分析のようにデータを柔軟に加工できるのがポイントです。
さらに、Bigqueyは通常「SQL」という言語で操作しなければいけませんが、この方法ならやりたいことを指示するとClaude側でコードを書いてくれるため、非エンジニアでも簡単に使えるというわけです。
【重要】セットアップの前に確認
必要なもの
今回必要なものは3つです。それぞれの設定方法は、このあと詳しくご紹介します。
- デスクトップ版のClaude
- Google Cloud(BigQueryを利用するために必要)
- Node.js
ちなみにClaudeのWeb版やClaude Codeなどを使っても問題ありませんが、MCPの設定が簡単なためデスクトップ版を使用しています。
注意事項
- 事前にGA4やSearch ConsoleとBigQueryを連携する必要があります(連携以前のデータ取得はできません)
- BigQueryは従量課金制です(90日間トライアルあり)
- 今回の方法は個人利用を想定しています。チームで共有して利用する場合、情シス部門などと連携してセキュリティリスクを考慮しつつ設定しましょう
- 💡BigQueryとGA4、サーチコンソールの連携方法は公式ページをチェック
-
GA4の連携方法
Search Consoleの連携方法
セットアップの全体像
セットアップは以下の4ステップです。約20〜30分ほどで完了するかと思います。
Step1:Google Cloudでサービスアカウントを作成
BigQueryを利用するためには、Google Cloudでサービスアカウント作成や鍵(JSONファイル)の作成が必要です。以下、手順を解説していきます。
Google Cloud Consoleにアクセス
まずはBigQueryを利用したいGoogleアカウントでログインして以下のURLにアクセスし、「無料で開始」をクリックしましょう。
https://console.cloud.google.com
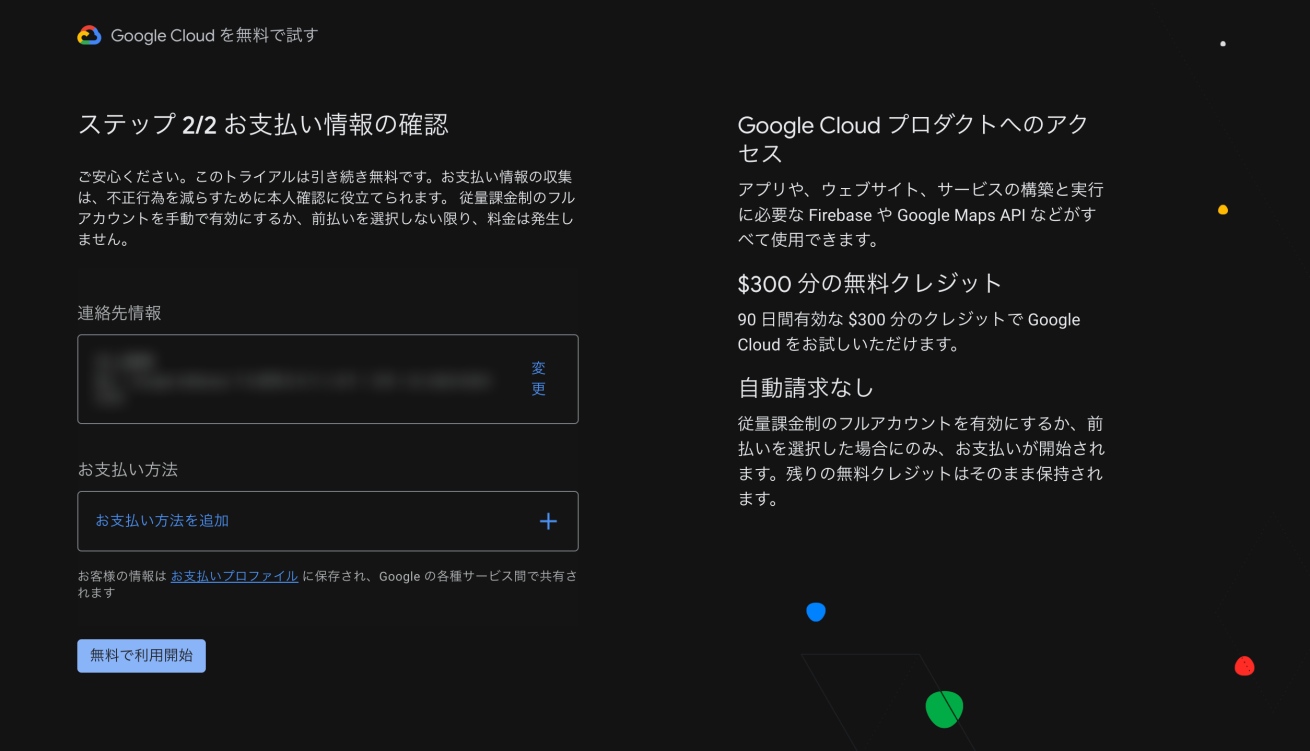
利用するためにはクレジットカードなど支払い方法の登録が必要です。ちなみに初回登録時はトライアルとして90日間使える300$分のクレジットがもらえます。
中小規模(GA4の月間イベント数が200万ほど)のサイトなら、基本的にはトライアルクレジットの範囲で十分まかなえるかと思います。
サービスアカウントを作成
登録完了後、コンソール(管理画面)が開きます。BigQueryを利用するためにはサービスアカウントが必要ですので、作成していきましょう。
💡サービスアカウント:Google Cloudの各種サービスに付与するアカウントのこと。各サービスが何をどこまで利用できるか権限を設定する、プログラム用の身分証明書のようなもの
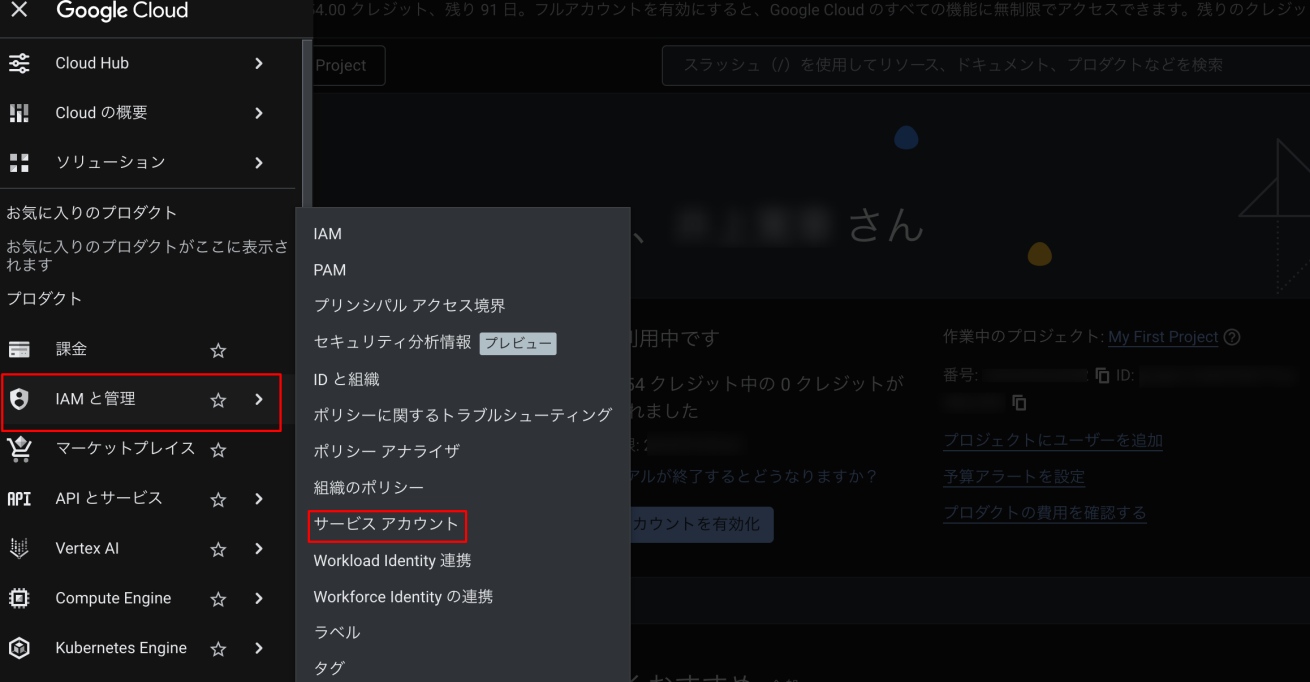
- 左上のメニューをクリック
- 「IAM と管理」→「サービスアカウント」を選択
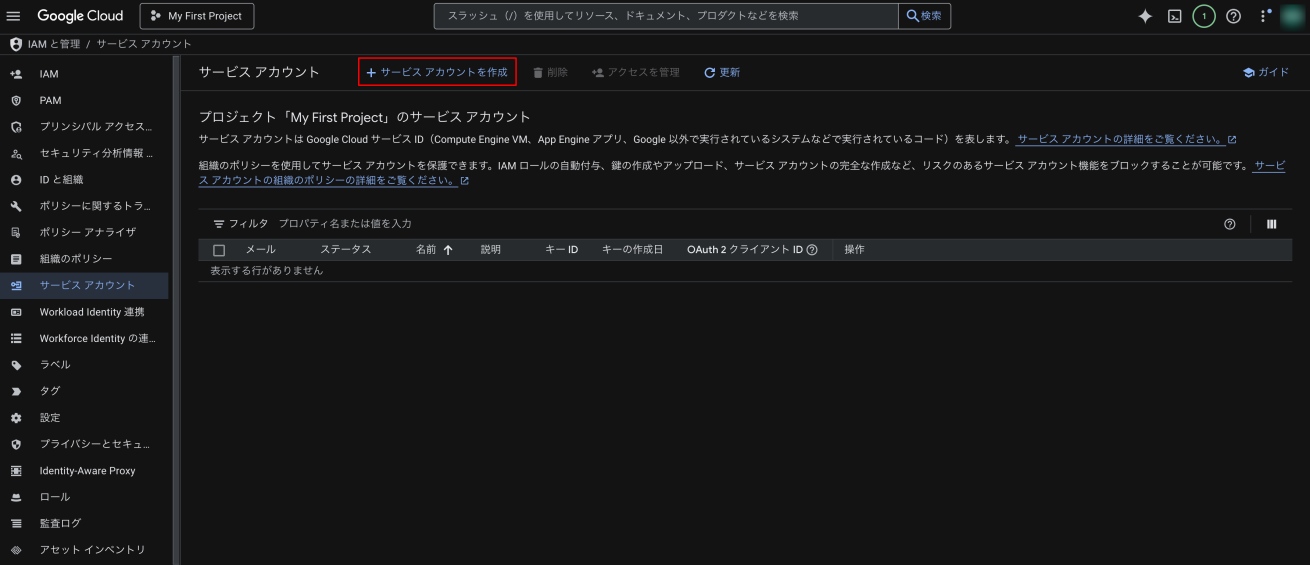
上部の「+ サービスアカウントを作成」をクリック。
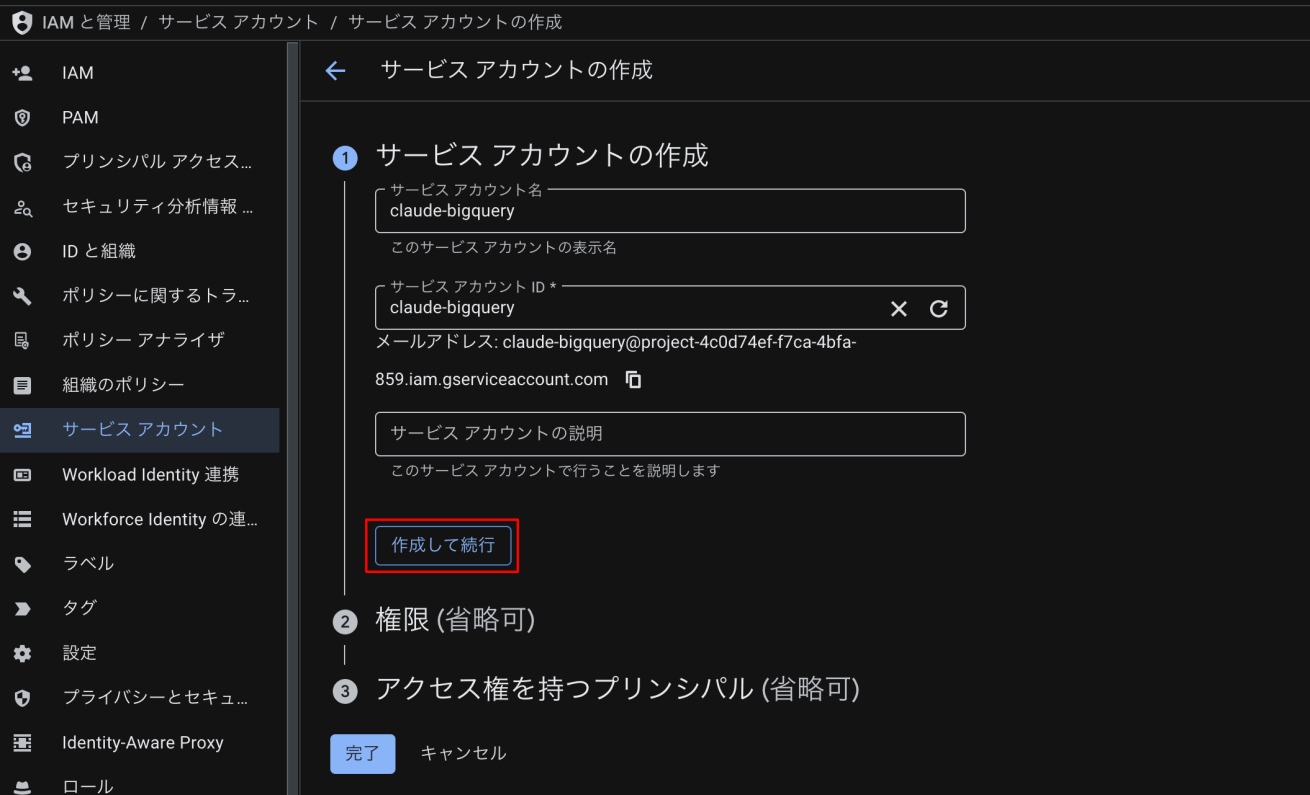
- サービスアカウント名:わかりやすい名前を入力(例:claude-bigquery)
- サービスアカウント ID:自動で入力されます
- 作成して続行をクリック
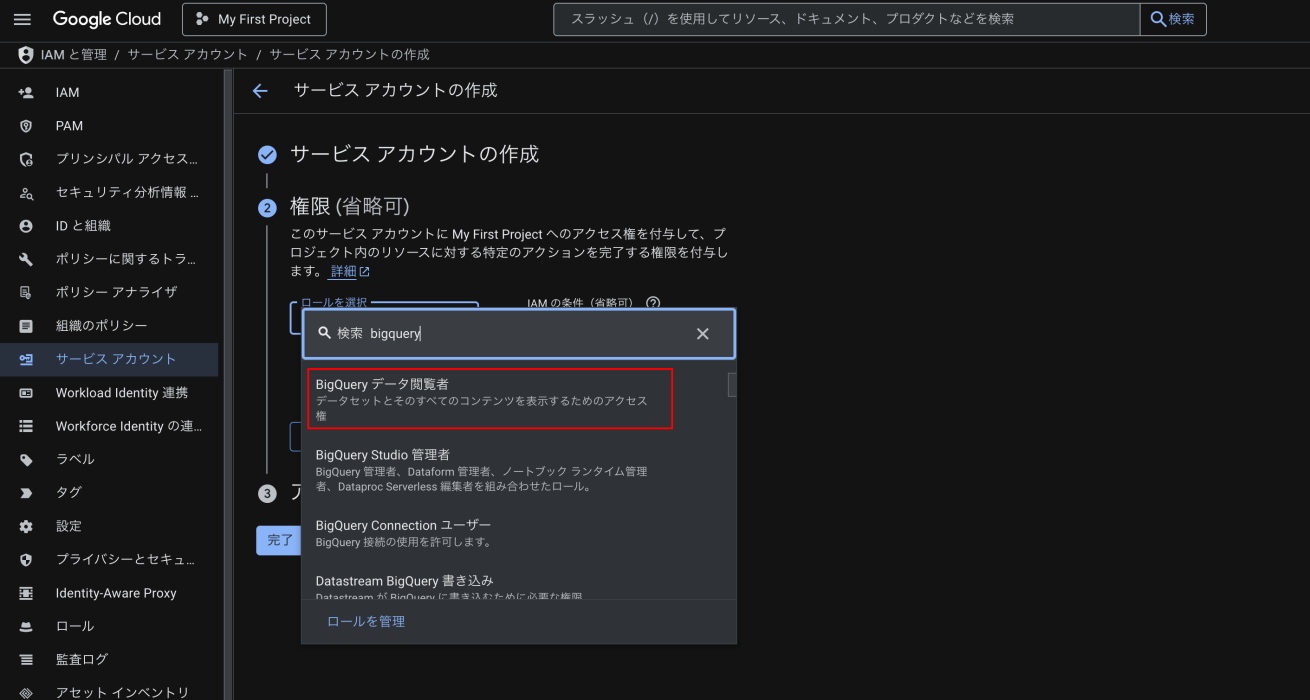
- 「ロールを選択」 をクリック
- 検索ボックスに「BigQuery」と入力
- 「BigQuery データ閲覧者」 を選択
- 続行をクリック
- 完了をクリック
💡初めてBigQueryを使う方は、データ上書きなどの事故を防ぐために「BigQuery データ閲覧者」を選びましょう。使い慣れてきたら必要に応じて他の権限を付与してください。
鍵(JSONファイル)をダウンロード
続いて、AIがBigQueryのデータにアクセスする許可証となる、鍵(JSONファイル)をダウンロードします。
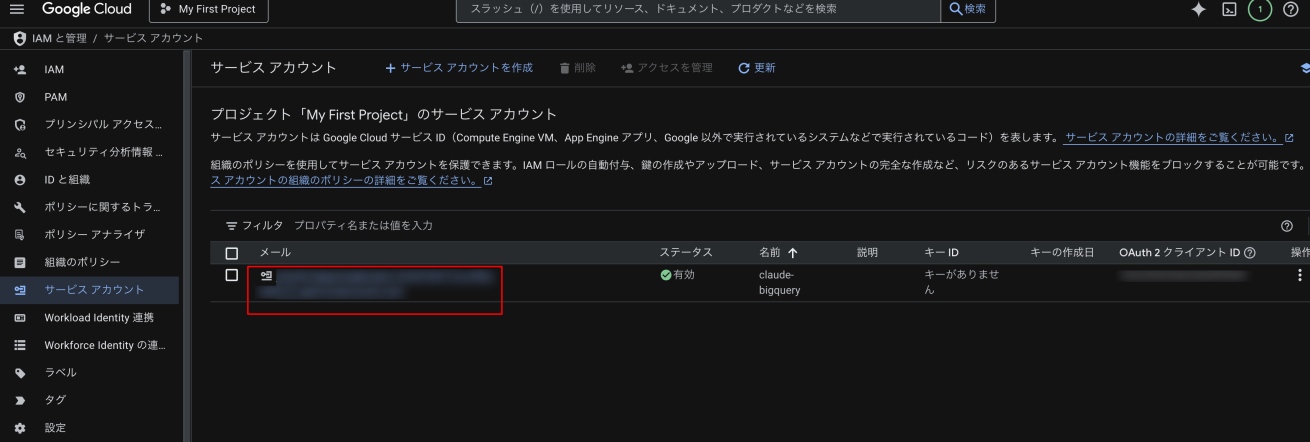
まずは作成したサービスアカウントのメールアドレス(赤枠部分)をクリック。
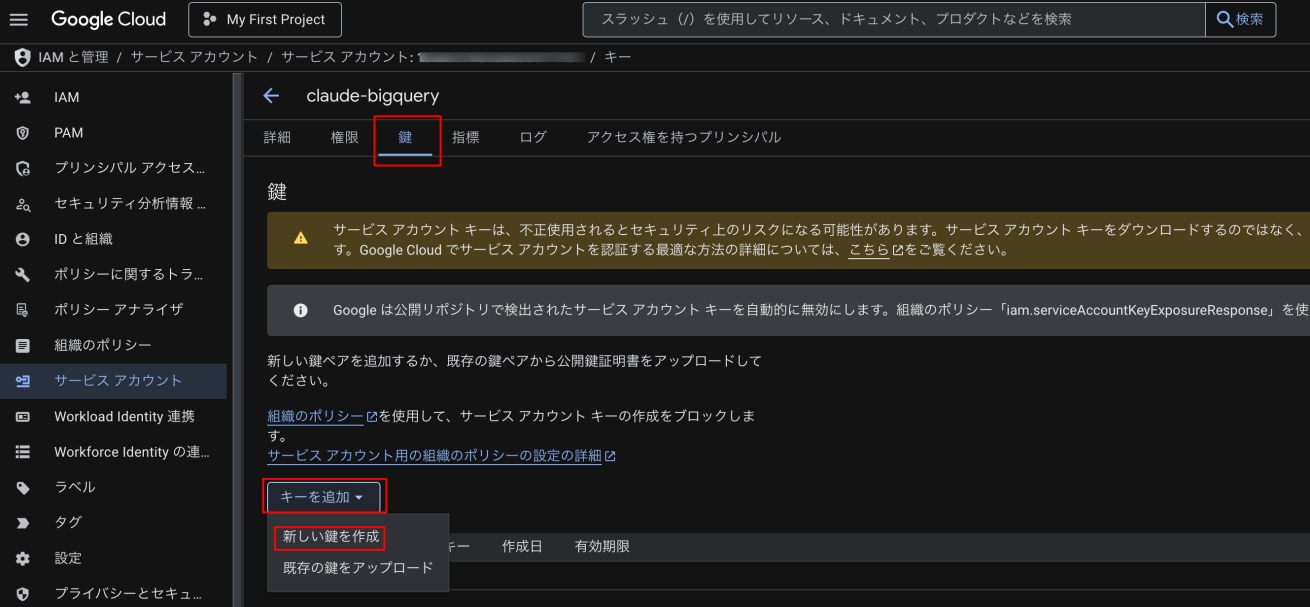
- 上部の「鍵」タブをクリック
- 「キーを追加」→「新しい鍵を作成」をクリック
- ウィンドウが表示されるので、「JSON」を選択して「作成」をクリック
- JSONファイル(鍵)が自動的にダウンロードされます
⚠️JSONファイル(鍵)は絶対に他人に共有しないでください。このファイルが外部に漏れると、外部の人もデータにアクセスできるようになるリスクがあります
ファイル名はclaudepass.jsonなど、わかりやすい名前に変更してOKです。
Step2:Node.jsのインストール
BigQuery MCPを動かすためには、Node.js(JavaScriptの実行環境)をインストールする必要があります。以下のURLからインストールを進めてください。
https://nodejs.org/ja/download
インストーラーのダウンロード方法
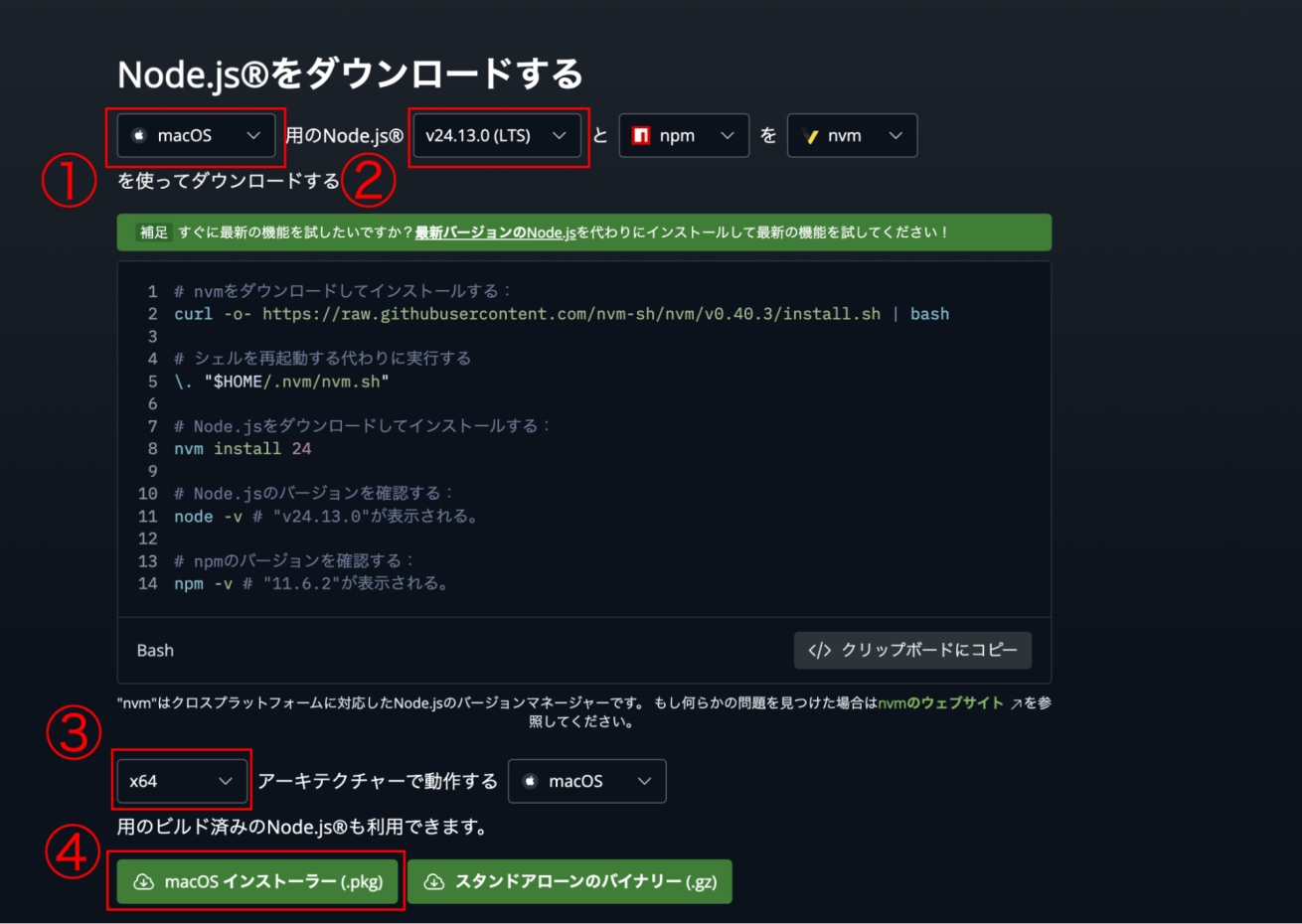
- 自分のOS(macOS / Windows)を選択
- 「LTS(推奨版)」 をダウンロード
- MacでM1〜M4 チップを使っている場合は「ARM64」を選択
- ダウンロードボタンをクリック
ファイルを開いて「続ける(Next)」をそのまま何度かクリックすると完了です!
インストールの確認
正常にインストールできているかも、以下の手順で確認しておきましょう。
- Macのターミナル(Windowsの場合はコマンドプロンプト)を開く
node --versionと入力してEnter
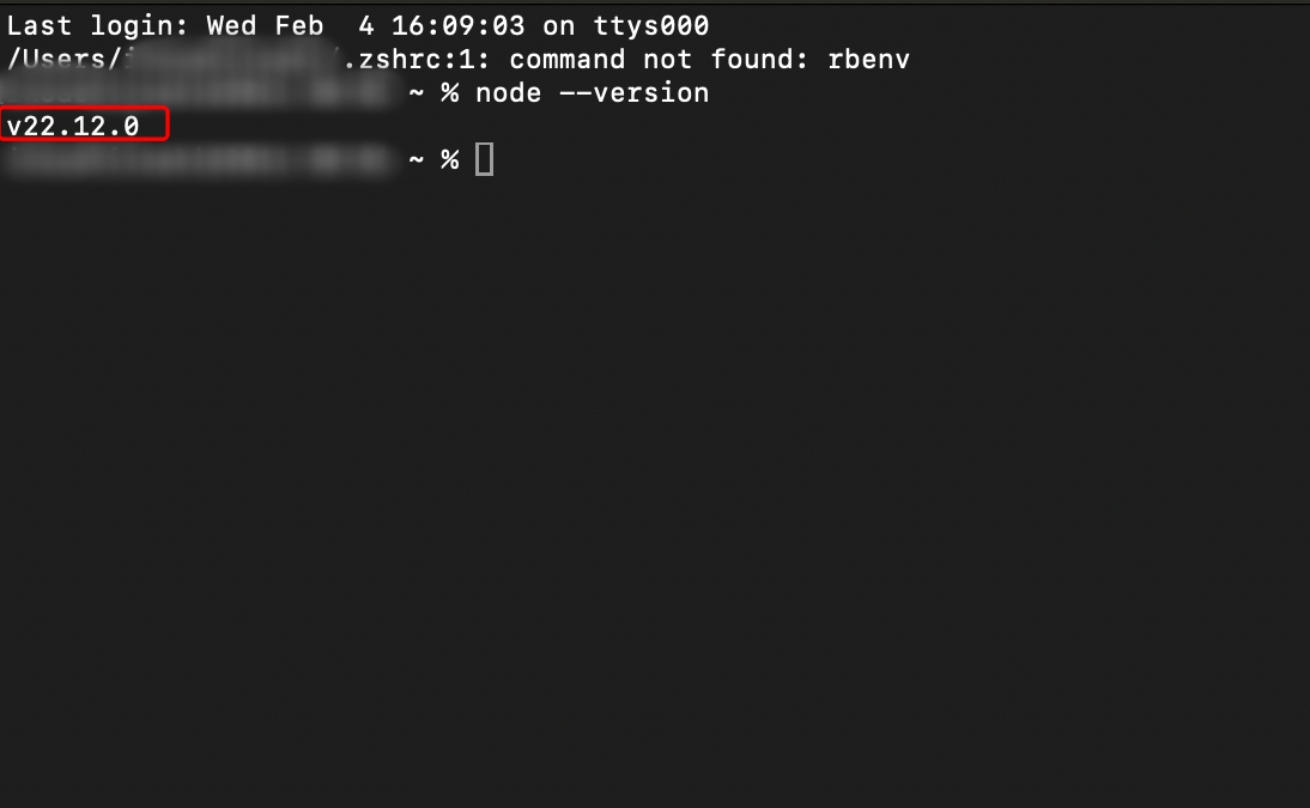
コードを実行後、v2x.x.xのように、自分がインストールしたバージョン名が表示されればOKです!
Step3:デスクトップ版Claudeの設定
いよいよClaudeとBigQueryを接続していきます。今回の方法ではデスクトップ版Claudeを使いますので、ダウンロードとサインインをしてください。
その後、以下の手順に従い設定を進めます。
設定ファイルを開く
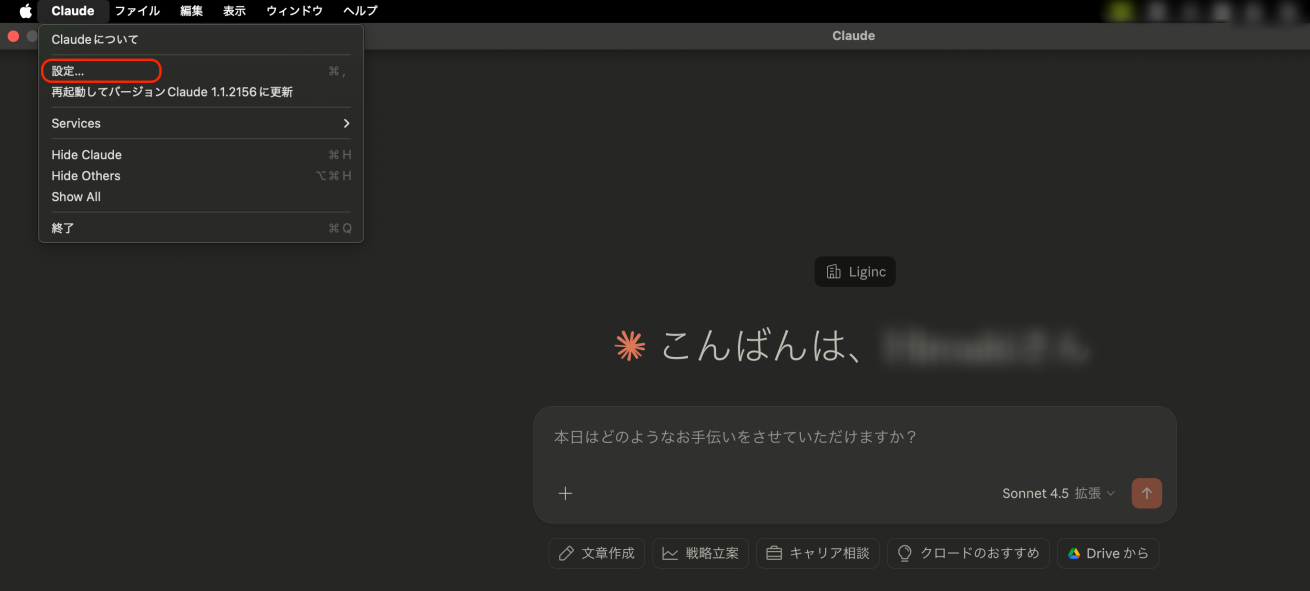
まずは上部メニューバーのClaude→設定(Windowsはファイル→設定)をクリックしましょう。
- 左側の「開発者」をクリック
- 「設定を編集」ボタンをクリック
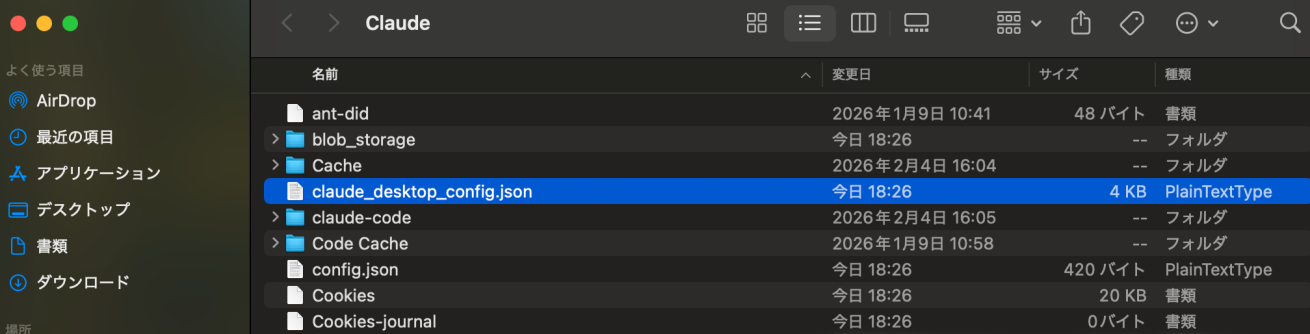
フォルダが表示されるので、claude_desktop_config.jsonというファイルをテキストエディターで開き、以下のコードをコピペして貼り付けてください。
{
"mcpServers": {
"bigquery": {
"command": "npx",
"args": [
"-y",
"@ergut/mcp-bigquery-server",
"--project-id", "あなたのプロジェクトID",
"--location", "asia-northeast1",
"--key-file", "JSON(鍵)の場所"
]
}
}
}
「あなたのプロジェクトID」と「JSON(鍵)の場所」は自分の環境に応じて書き換えてください。
| 書き換える箇所 | 確認方法 |
|---|---|
あなたのプロジェクトID |
利用するBigQueryのデータがあるプロジェクトIDを記載する。GCPコンソール(https://console.cloud.google.com)の左上に表示されています |
JSON(鍵)の場所(JSONファイルのパス) |
Step1で保存したJSONファイルの場所を記載 例:/Users/{自分のPCのユーザー名}/Downloads/{さきほど保存した鍵のファイル名}.json |
※Windowsではパスの区切りに\\(バックスラッシュ2つ)を使います。
ここまでできたら、ファイルを保存したあとClaudeを再起動してください。
Step4:動作確認
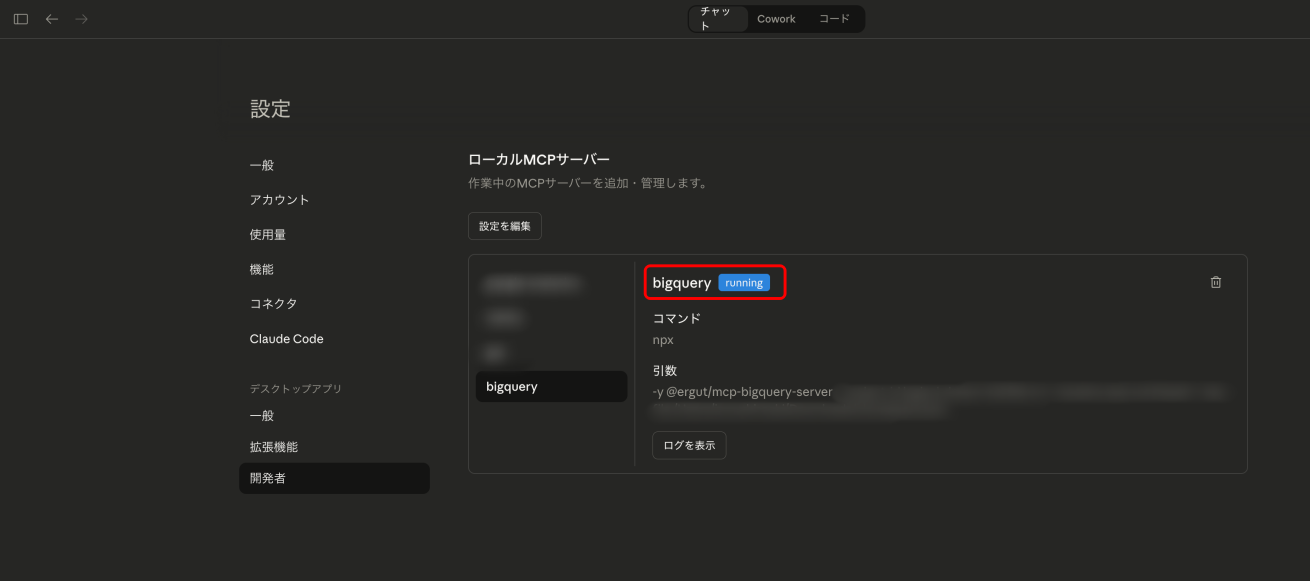
BigQueryとClaudeが接続できているか確認していきます。さきほどと同様、メニューバーの「設定」→「開発者」を開いてください。
以下のように、bigqueryの箇所に「running」と表示されていれば準備完了です!
実際にサイトを分析してみよう
セットアップができたら、正しくデータ分析できているか試してみましょう。使い方の例をいくつかご紹介します。
🔰 1.数値状況の確認
| 分析内容 | プロンプト例 |
|---|---|
| 自然言語で簡単にフィルターをかける | 2026年1月のサイト全体のセッション数を日次で出して ◯◯を含む先月の流入キーワードを一覧で出して |
📊 2.データをもとに分析する
| 分析内容 | プロンプト例 |
|---|---|
| 流入元分析 | 先月の参照元/メディア別のセッション数とCV数(キーイベント◯◯の数値)を確認し、CVRが落ちているメディアを調べて |
| ランディングページ別パフォーマンス | 先月のランディングページ別に以下を集計し、CVRが高い順に上位20件を表示してほしい – セッション数 – UU数 – CV数(キーイベント◯◯の数値) – CVR |
🚀 3.分析結果から改善案を出す
| 分析内容 | プロンプト例 |
|---|---|
| CVしたユーザーの行動を特定 | 過去7日間で説明会を予約したユーザーのLPと、予約完了までの遷移経路をすべて洗い出してほしい。その後、CVしたユーザー・しなかったユーザーの特徴を判別してLP改善案を出してほしい |
| 広告キャンペーンの効果測定 | 先月のGoogle広告キャンペーン別(utm_campaign別)に以下の数値を集計して。キャンペーンごとに費用対効果の優劣をまとめて、改善案を出してほしい – クリック数(セッション数) – CV数 – CVR |
💡 より良い回答を得るコツ
| コツ | 例 |
|---|---|
| 期間を明確に | 「先月」「過去30日」「2026/1/1〜1/31」 |
| CV定義を指定 | 「CV = /contact/thankyou に到達したUU」 「CV = キーイベント名◯◯」など |
| 出力形式を指定 | 「表形式で」「CSVで出力して」 |
| 件数を指定 | 「上位20件」「100件まで」 |
| 比較軸を指定 | 「前月比」「前年同月比」「デバイス別」 |
よくある質問
Q.「BigQuery が表示されない」またはClaudeを表示したらエラーになった
ほとんどの場合、以下どちらかの手順で解決します。
- Node.jsがインストールされているか確認(手順を見る)→エラーが出たら再インストール
- Claudeの設定ファイルを確認→Cluadeにコードを渡して、エラーの原因を特定してもらう
💡設定ファイルでよくある間違い
- プロジェクトIDが違う
- JSONファイルのパスが違う
- カンマの位置、閉じカッコなど、Claudeの設定ファイル自体のコード(JSON)が間違っている
Q.「テーブル/データが見つからない」と言われた
BigQueryと各ツールの連携ができていない場合があります。BigQuery内のデータセットにデータが入っているか確認しましょう。
Q.分析中にエラーが多発する
基本的には放置しておけば自動で解決してくれますが、使っていると「毎回同じエラーが出てるな……」という場面が出てくると思います。
そんなときは、Claudeの機能であるSkillsを活用するのがおすすめです。
- Skillsとは
- タスクを実行するために必要な指示やスクリプトなどをまとめたファイル群のこと。頻度の高い作業をSkill化しておくことで、毎回同じ指示をせずにClaude側で処理してくれます。
毎回同じエラーが出る場合は、原因が「前提条件の抜け」や「クエリ手順のぶれ」にあることが多いです。そうした「いつもの確認・切り分け」を固定化できるのがSkillsです。
使い方は簡単で「いま実行した内容をSkill化して」などとチャットで指示するだけでOK。BigQueryだけでなく、他のタスクでも活用できます。
Q.セキュリティは大丈夫なの?
必ず以下の点を理解した上で利用してください。
外部に送信されるデータについて
今回設定したMCPサーバー自体は外部通信を介さずにPC上で動作しています。しかし、BigQueryから取得したクエリ結果(≒GA4やSearch Consoleのデータ)は、Claudeが回答を生成するためにAnthropic社のサーバーに送信されます。
Anthropicのプライバシーポリシーでは、有料プラン(Pro / Team / Enterprise)の場合、ユーザーの入力データをAIモデルのトレーニングに使用しないと明記されています。ただし、Anthropic社からデータが流出する可能性もゼロではないため、個人情報や機密データを含む分析を行う場合は、自社のセキュリティポリシーと照らし合わせた上で利用しましょう。
サービスアカウントの鍵(JSONファイル)の管理
Step 1で作成したJSONファイルは、BigQueryへのアクセス権そのものです。他人に共有したり、ドライブ上にアップしたりしないようご注意ください。もし紛失・流出した場合は、すぐにGoogle Cloud Console上で鍵を無効化してください。
まとめ
BigQueryを利用すればさまざまなデータを組み合わせて柔軟にサイト分析ができます。生成AIの力を上手く借りながら日々の業務を効率化し、自分が向き合うべき本質的な業務に集中できるよう、作業環境を設計するためのヒントになれば幸いです。
他にもLIGブログの生成AI活用術を公開します!

3/13(金)20時より、LIGブログのSEOを担当している私あっきーの生成AI活用例をお伝えするセミナーを行います!
- 当日の内容
-
- 記事作成やリライトの自動化方法
- より実践的なBigquery×Claude活用法
- 実務で使っているプロンプトをプレゼント!
- こんな方におすすめです
-
- SEO施策を任され始めたが、何から考えるべきか悩んでいる
- 記事制作・分析・改善を少人数(または1人)で回している
- 生成AIを使ってみたが、表面的な使い方で止まっている
- マーケターとして、次のステップに進みたい
| 開催日時 | 2026年3月13日(金)20:00〜21:00 |
|---|---|
| 参加費 | 無料 |
| 使用ツール | Zoomウェビナー |
| 参加対象 |
|
| 参加方法 |
|
| お願い |
|
※こちらのセミナーは終了しました










