
こんにちは。エンジニアのヤスタカです。
最近はほぼ毎日、AIだの機械学習だのディープラーニングだのという言葉を聞くようになりましたね。それだけ重要な技術なのでこれからもどんどん発展していくのでしょうが、正直人工知能が内部でどんな処理をして結果を返しているのか、さらっと説明を聞いてもちんぷんかんぷんでよくわからないことが多い。。。
とりあえず難しい理屈は抜きにして、機能を利用してみることから始めるのもいいのではないでしょうか?
今回はGoogleがAPIとして提供しているGoogle Cloud Visionを使って、画像認識をしてみたいと思います。
google cloud API
Googleには、APIとして利用できる機能がざっと100以上も用意されています。今回ご紹介するGoogle Cloud Visionなかのひとつで、Googleの機械学習の画像認識APIです。
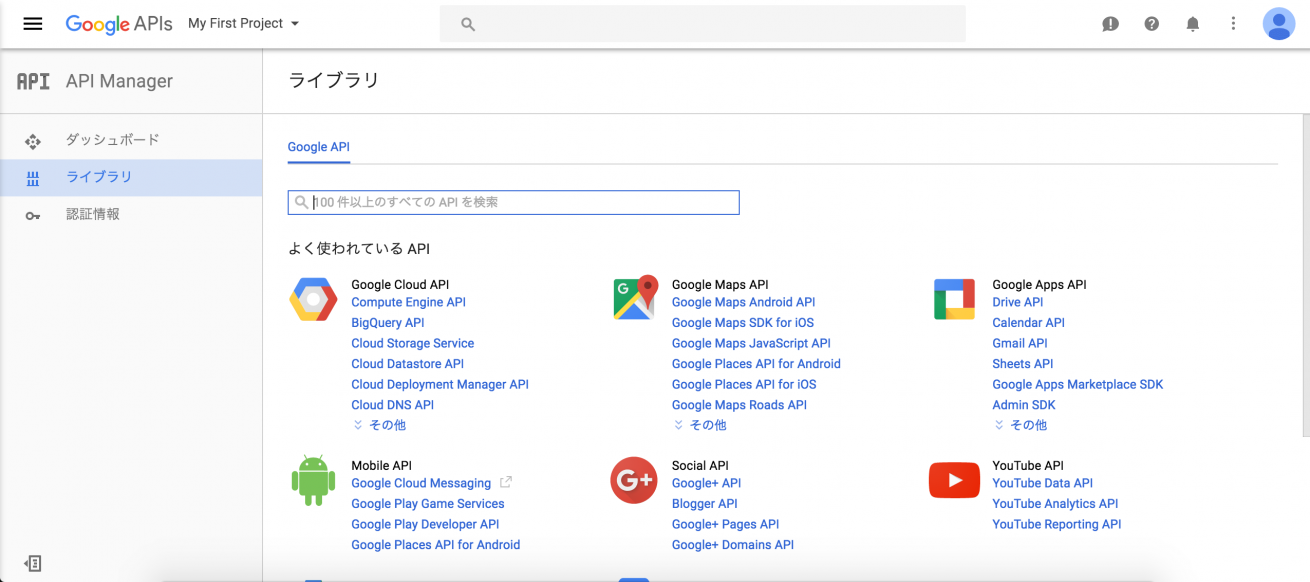
まずは本APIを使用するためのコンソール画面を開きましょう。
プロジェクトの作成
Google APIを使用するには、いくつか事前準備が必要です。まずはコンソール画面の左上メニューから「プロジェクトの作成」を選択します。
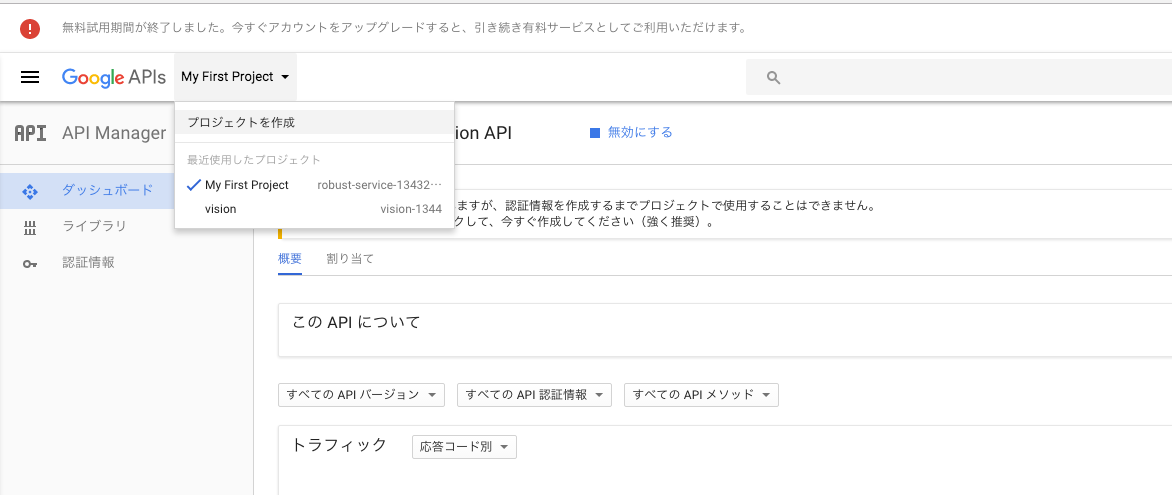
このときにプロジェクトの名前をつけるのですが、とりあえずなんでもいいです。デフォルトで入っている「My Project」でいいかと思います。
支払い情報の入力
Google Cloud Vision APIを利用するには、請求書情報が必要です。課金が発生しない範囲内で使用する場合でも必要な登録項目なので、入力しておきましょう。左上のメニューから「お支払い」を選択して、必要事項を記入します。
API認証情報
続いて、APIの認証情報を登録します。左上の検索ウィンドウに「cloud vision」と入力してみてください。
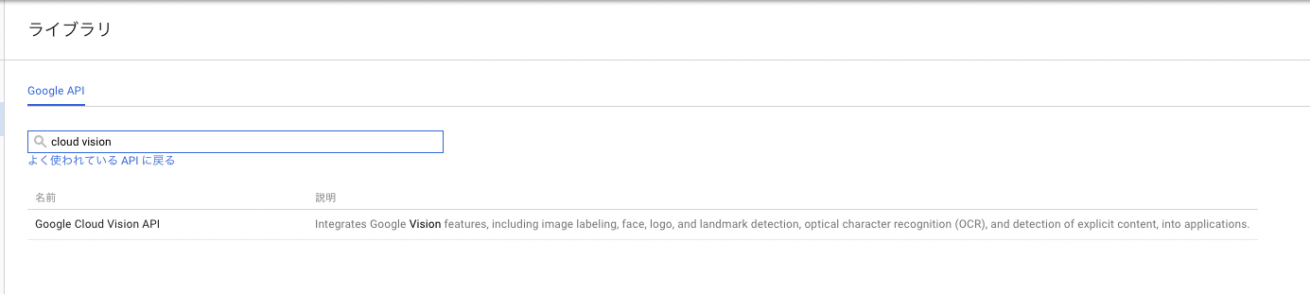
Google Cloud Vision APIが見つかったら、クリック。認証情報に進んでください。
画面に促されるまま、入力していきます。認証情報の入力を進めていくとAPIキーが発行されるので、そちらは漏れないようにしっかり管理しておきます。
Google Storageにbucketを作成して画像をアップロード
今回はより手軽にするために、クラウド上に画像をアップロードして、その画像を認識してみます。まずは「Google Strageサービスの利用」を開始して「bucket」(データ置き場のようなもの)を作成し、以下のリンク先からダウンロードした画像をアップロードします。bucket名はなんでもいいのですが、全世界でユニークになる必要があります。
画像認識をしてみる
こちらのページへと飛んで、「gcsImageUri:」の部分にあるbucketという文字を、先ほど作成したbucket名に変更してください。そしてAUTHORIZE AND EXECUTEボタンを押すと、以下のような結果が返ってきます。
200 - SHOW HEADERS - { "responses": [ { "labelAnnotations": [ { "mid": "/m/0bt9lr", "description": "dog", "score": 0.96969336 }, { "mid": "/m/04rky", "description": "mammal", "score": 0.92070323 }, { "mid": "/m/09686", "description": "vertebrate", "score": 0.89664793 }, { "mid": "/m/039ndd", "description": "setter", "score": 0.6906004 }, { "mid": "/m/01z5f", "description": "dog like mammal", "score": 0.68510407 } ] } ] }返ってきた結果を見ると、[mammal=哺乳類][dog=犬][setter=セッター]などの情報が入ってますね。なんと犬種まで判定しています! すごい!
先ほどは "type":LABEL_DETECTION と指定しましたが、これは画像の種類を判定するときに使います。空、食べ物、犬などに何が写っているかを判定してくれるのです。
次は、LABEL_DETECTIONのところをFACE_DETECTIONに変更して、こちらの画像を認識させます。
すると、目の位置や口の位置などのいろんな情報が返ってきます。この写真では分身しているのですが、そこはさておき、人の表情などを判定する箇所で以下のような結果が返ってきました。
"joyLikelihood": "VERY_UNLIKELY", "sorrowLikelihood": "VERY_UNLIKELY", "angerLikelihood": "VERY_UNLIKELY", "surpriseLikelihood": "VERY_UNLIKELY", "underExposedLikelihood": "VERY_UNLIKELY", "blurredLikelihood": "VERY_UNLIKELY", "headwearLikelihood": "LIKELY"最後、帽子を被っているかどうかの判定がLIKELYになっていました。分身していても分かるってすげー。
その他、LANDMARK_DETECTIONというオプションを指定すると、写真に写っている景色から、どこのランドマークもしくは観光名所などを判別してますし、FACE_DETECTIONを指定すると顔を認識してくれ、さらにその表情から怒っているのか、悲しんでいるのか、笑っているのかなど、表情まで判定してくれます。
まだまだ精度は荒い部分もありますが、今後どんどんその精度は改善されていくと思われます。
他にもいろいろなオプションが用意されているので、興味ある方はぜひ一度試してみてください!
LIGはWebサイト制作を支援しています。ご興味のある方は事業ぺージをぜひご覧ください。










