
インターネットのみなさんこんにちは。みなさんは、自力で文章を書いていますか?
僕はもう無理です。企業からのメールの返信、上司からのSlackメッセージ、活動報告書。何か文章を書く前に、ChatGPTに投げています。ここだけの話、友人からのLINEの返信にもAIに頼もうか悩むぐらいです。 さて、そんな僕がふと気づいたことがあります。
個人情報とか気にせずにAIに投げたい!!
個人情報をマスキングして「◯◯さん」と置き換えたり、NDA違反にならないように具体的な内容を削ったりしているのですが、わざわざAIに投げる前に加工してから出てきたものを再加工するというプロセス自体がめんどくさい。結局一度直すのであれば意味がありません。
そこで思い出したのがローカルLLMの存在です。
自分のPC上でローカルにLLM(Large Language Model、大規模言語モデル)を動かせば、機密情報が外部に漏れる心配はありません。2025年3月にGoogleがGemma 3をリリースし、2025年8月にはOpenAIがgpt-ossをリリースするなど、ローカル環境で動作するモデルが続々と公開されています。
今回は、ChatGPTライクに動かせる比較的操作の簡単なLM Studioを使って、ローカルLLM環境を構築してみましょう。
- “AIを安全に使える”スキル、案件に活かしませんか?
- LIGではWeb制作・システム開発会社ならではの知見を活かしたフリーランスエージェント「LIGエージェントアサイン」を運営しています。あなたのAIスキルを活かせる案件もご紹介可能です!
→サービス詳細を見る
目次
※本記事の内容は2026年1月時点の情報をもとに執筆しています。紹介しているAIツールの仕様やライセンス条件は変更される可能性があります。最新情報や商用利用に関する詳細は、必ず各サービスの公式サイトおよび利用規約をご確認ください。
LM Studioとは
LM Studioは、ローカルPC上でLLMを動作させるためのGUIアプリケーションです。ChatGPTのような対話型インターフェースを持ち、オープンソースで公開されているLLMであれば、PCスペックの範囲内で好きなモデルを選択できます。
API料金が不要で、データが外部に送信されない点が特徴です。また、テキストファイルやPDFなどのドキュメントを読み込ませて参照させることもでき、ファイルの読み込みから処理まですべてローカル環境で完結します。
快適に動作させるには、16GB以上のRAM(メインメモリ)が推奨されています。
それってクラウドのAIでよくないですか?
正直なところ、大半の用途ではクラウドAIの方が応答速度も精度も上です。ただし、以下のような「機密情報を扱う場面」では、性能よりもセキュリティが優先されます。
- 顧客の個人情報を含むメールの分類・要約
- 社内の人事評価コメントの添削・修正
- 未発表プロジェクトの議事録要約
- 契約書や提案資料のドラフト作成
また、クラウドAIには利用規約やデータ保持ポリシーの懸念※もあります。「学習に使われないと書いてあるけど本当?」という不安を完全に払拭できないなら、ローカルという選択肢も十分アリです。
- ※補足:「クラウドは本当に危険なのか?」
- ChatGPTをはじめとした主要サービスは、セキュリティ対策が施されており、通常の用途では問題ありません。ただし、企業の情報管理ポリシーや業界規制(個人情報保護法、NDAなど)によっては、「万が一」のリスクすら許容できない場合があります。ローカルLLMは、そうした「絶対に外に出せない情報」を扱うための選択肢です。
ローカルLLMは本当に安全?
ローカルで動かせば情報漏洩の心配がないと書きましたが、これは「外部サーバーに送信されない」という意味であり、完全に安全というわけではありません。ローカル環境特有のリスクを理解しておきましょう。
LM Studioは、チャット履歴だけでなく、アップロードしたドキュメント(PDF、テキストファイルなど)もローカルに保存します。共有PCやパブリックなアカウントで機密情報を扱うと、以下のようなリスクがあります。
- 他のユーザーがチャット履歴を閲覧できる
- アップロードした社外秘ドキュメントがPC内に残り続ける
- 削除したつもりでも、ファイルシステム上に痕跡が残る可能性がある
機密情報を扱う場合は、以下の対策を取りましょう。
- 個人専用のPC(社用PC)やスタンドアロンのPCで作業する
- 作業後はチャット履歴を削除する
- アップロードしたファイルの保存場所を確認し、不要になったら削除する
- 特に機密性の高い情報を扱う場合は、作業終了後にLM Studioのデータフォルダごと削除することも検討する
また、LM Studioはローカルで動作しますが、モデルのダウンロードやアップデート確認時にはインターネット接続が必要です。また、一部の機能(モデル検索など)はオンライン前提です。
インストール手順
1. LM Studioのダウンロードとインストール
公式サイトからお使いのOSに対応するインストーラーをダウンロードします。
2. モデルを検索する
インストール後、LM Studioを起動してモデルのダウンロードを行いましょう。画像のように検索ボタンからモデル一覧を表示できます。
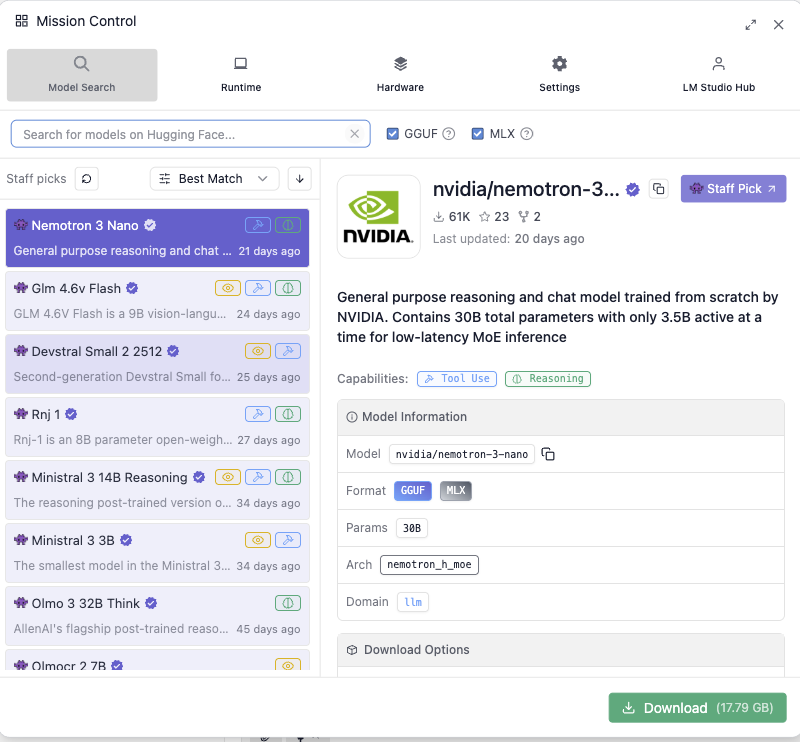
デフォルトの設定であれば、そのモデルを動かすのに必要な要件を満たしたモデルのみが表示されます。
モデルの選び方については、次の項で詳しく説明しています。
3. モデルのダウンロード
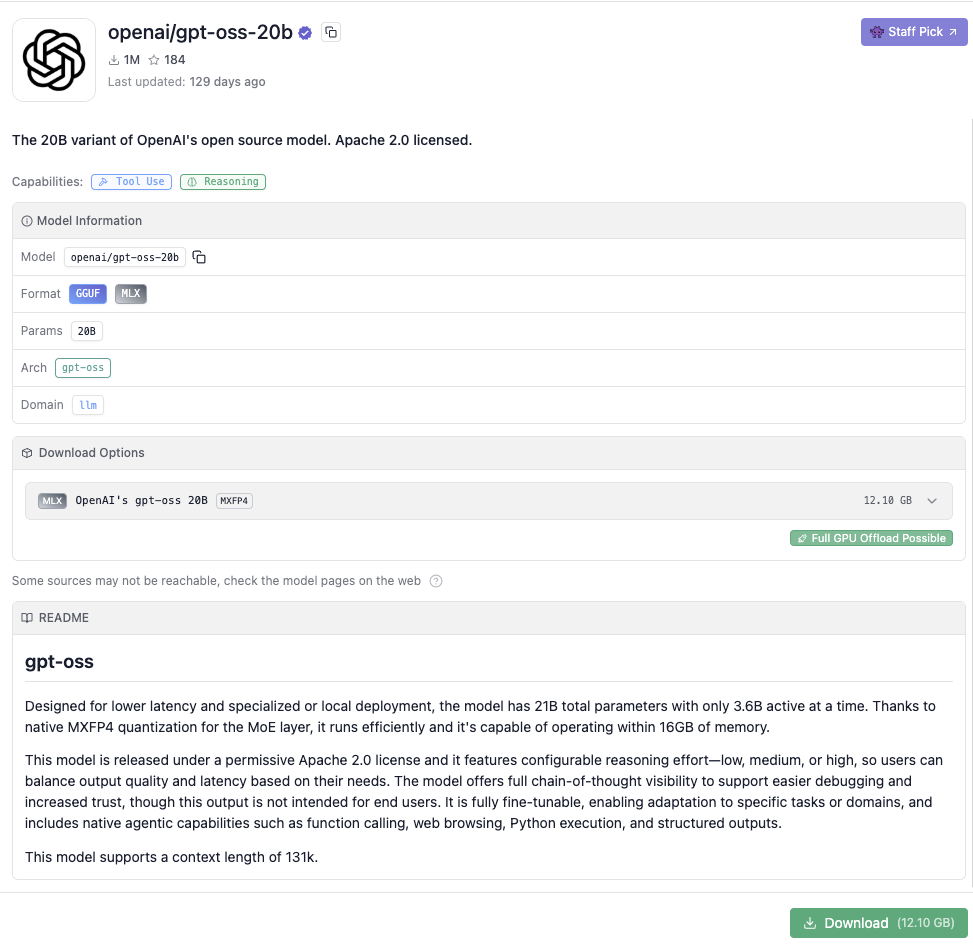
今回はgpt-oss-20bを使用します。16GBのVRAMが推奨されます。
モデルを選んだらダウンロードしましょう。その間にコーヒーでも淹れて待ちましょう。
【重要】モデルの選び方
モデル選びは、ローカルLLMの使い勝手を大きく左右します。ここでは3つの観点から詳しく解説します。
安全なモデルを選ぶ
LM Studioでダウンロードできるモデルは、主にHugging Face(AIモデルやデータセットを共有するプラットフォーム)などのリポジトリから取得されます。有名なモデルであれば問題ありませんが、出所不明のモデルには注意が必要です。
2024年にセキュリティ研究者が約100個の悪意あるモデルをHugging Faceで発見しており、これらはユーザーのPCにバックドアを設置できる実例が確認されています。LM Studioで使用されるファイルフォーマットでも、モデルロード時に任意のコードを実行できる脆弱性が存在します。
- 公式または信頼できる組織がアップロードしたモデルを選ぶ
- ダウンロード数やコミュニティの評価を確認する(ただし、人気があるからといって安全とは限らない)
- このような、Hugging Faceの”Unsafe”警告が表示されたモデルは避ける
- 有名企業を装った偽アカウントに注意(MetaやOpenAIなどの認証済みバッジを確認)
LM Studio内で検索上位に出てくる主要なモデル(lmstudio-communityなど公式アカウント)は基本的に問題ありませんが、個人がアップロードしたマイナーなモデルや、カスタマイズ版を試す場合は自己責任で。
スペックに合ったモデルを選ぶ
ローカル環境でLLMを動かすには、それなりのスペックが要求されます。特に重要なのが、VRAM(ビデオメモリ)です。
Windows/LinuxとMacで、以下のような違いがあります。
| Windows/Linux(NVIDIA GPU搭載) | GPUに搭載されているVRAM容量が基準になります。 例:RTX 4060(VRAM 8GB)なら、ファイルサイズが8GB以下で動作見込み(その他の環境に依存) |
|---|---|
| Mac(Apple Silicon) | 統合メモリアーキテクチャのため、システムメモリ全体を使用できます。 例:M1 Mac 16GBなら、モデルサイズが12GB程度まで動作可能(その他の環境に依存) |
これは正確な判断方法ではないのですが、目安としてモデルファイルサイズの1.2〜1.5倍程度のVRAMが必要と考えるとわかりやすいです。LLMはVRAMにすべてのデータを割り振ることで、高速応答を実現します。
しかしながら、ここに会話の履歴やユーザー指示などといった情報が加わることで、実際にはモデルサイズよりも大きなVRAM容量が要求されます。そのため、LLMが動作するか不安な方は、選択したモデル下部のサインを見ることをおすすめします。
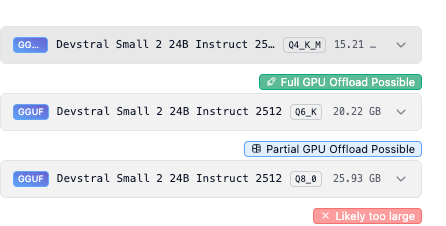
- Full GPU Offload Possible:GPUのVRAMにデータを割り振りできるので、高速応答ができます。
- Partial GPU Offload Possible:GPUのVRAMに部分的にデータを割り振り、残りをRAMに割り振ります。速度が犠牲になりますが、精度の高いモデルを運用したい場合におすすめです。
- Likely too large:スペック不足です。どうにもなりません、諦めて軽量モデルを検討しましょう。
スペック不足の場合は、Gemma 3n(Google)やNemotron 3 Nano(Nvidia)といった軽量モデルで試してみましょう。
モデル名で判断する
モデル名にはさまざまな記号がついていますが、重要なのは主に3つです。
パラメータ数(8B、4Bなど)
モデルの規模を表す数字です。B = Billion(10億)、M = Million(100万)を意味します。数字が大きいほど賢くなりますが、負荷が大きくなります。
量子化レベル(Q4、Q5、Q8など)
同じパラメータ数のモデルを圧縮して軽量化したバージョンです。精度と引き換えにファイルサイズを削減します。
- Q8:高精度だが重い
- Q5、Q4:精度と軽さのバランスが良い(おすすめ)
- Q3、Q2:とても軽いが精度が落ちる
同じパラメータ数で複数の量子化版がある場合、まずQ4やQ5を試してみましょう。動作が重ければQ3、余裕があればQ8を検討します。
フォーマット(GGUFやMLX)
LM Studioで扱えるモデルの形式です。
- GGUF:Windows/Linux/Macすべてで使用可能
- MLX:Mac(Apple Silicon)専用。Macの場合は高速化の可能性あり
いったん動かしてみる
ダウンロードが完了したら、実際にモデルを動かしてみましょう。

画面中央上部の「select a model to load」からダウンロードしたモデルをクリックするとモデルがVRAM上に展開されます。

ロードが完了するまで数秒〜数十秒かかります。
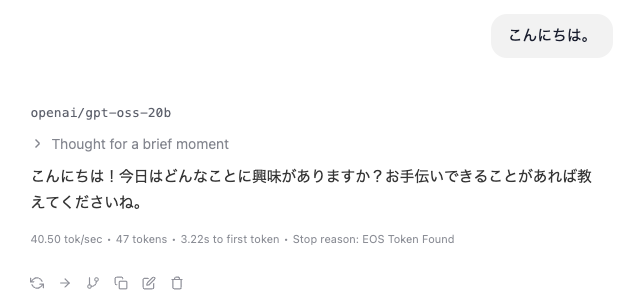
モデルのロードが完了したら、画面下部のチャットボックスに「こんにちは」と入力してみましょう。Enterキーを押すと、AIが応答を返してくれます。応答速度は使用しているPCのスペックやモデルのサイズによって変わります。

モデルをアンロードする際は、画面中央上部の「Eject」ボタンを押してモデルをアンロードしましょう。これによりVRAM上のデータがクリアされ、メモリが解放されます。チャット履歴は保存されるので、次回ロード時にも過去の会話を参照できます。
ファイルを読み込ませて活用する
LM Studioでは、テキストファイルなどをアップロードしてAIに読み取らせられます。たとえば以下のような活用ができます。
- 自分の過去の文章を読み込ませて、文体を学習させる
- 社内ドキュメントを読み込ませて、Q&A形式で回答させる
- 議事録を読み込ませて、要点を抽出させる
LM Studioでの対応フォーマットは、txt, docx, doc, pdf, csvに対応しています(最大30MB)。ただしPDFは内部構造が複雑なため、読み取りに余分なトークンを消費します。できれば、txtやdocxといった読み取り処理が軽いフォーマットがおすすめです。
実際にテキストファイルを読み込ませて要約させてみましょう。
- チャット画面の添付アイコンをクリック
- 読み込ませたいファイルを選択
- プロンプトを入力
- 結果を確認
ちなみに、LM Studioはファイルの長さによって処理方法が自動的に切り替わります。
- 短いファイル:モデルのコンテキストに収まる場合、ファイル全体をそのまま読み込みます
- 長いファイル:RAG(Retrieval-Augmented Generation)を使用し、質問に関連する部分だけを抽出してモデルに提供します
本来のRAGは、大量のドキュメントをベクトルデータベースに格納し、質問に関連する部分だけを検索・取得してLLMに渡す仕組みです。LM Studioはこの処理を自動化し、長いファイルに対してRAGを適用します。
出力スタイルをカスタマイズする
ダウンロードしたLLMは、そのままでも使えますが、毎回「ですます調で」「箇条書きで」などと指示を出すのは面倒です。状況に応じて使う指示のテンプレートが決まっている場合、LM Studioのプリセット機能を使えば、あらかじめ出力スタイルを指定できます。
設定手順
- アプリ下部のモードを「Power User」または「Developer」に切り替え

- 画面右上部の設定アイコンをクリック
- 「System Prompt」欄にカスタム指示を入力
- 「Save as Preset」で保存
指示のコツ
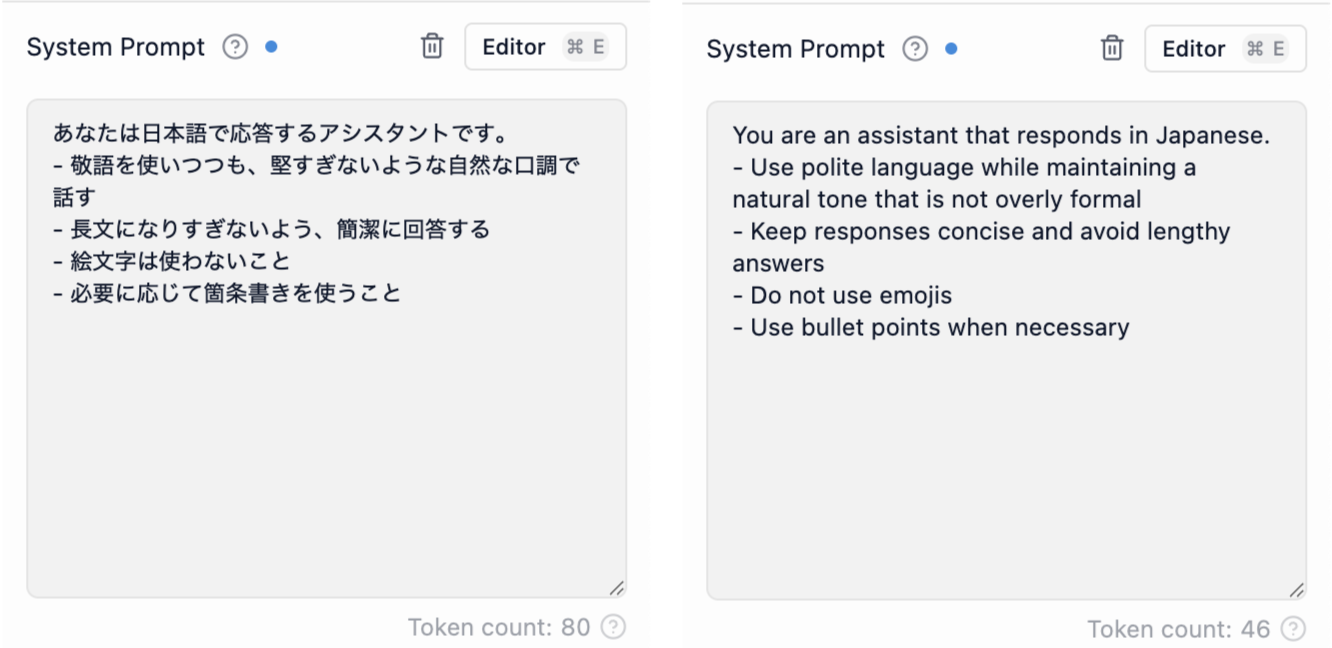
カスタム指示の量に応じてトークン(AIが処理するテキストの単位)を消費します。毎回の応答でその指示を処理する分だけ時間がかかるうえ、LLMが一度に扱える情報量(コンテキスト)には限界があるため、長い指示を設定すると、その分だけ会話内容に使える容量が減ってしまいます。指示は簡潔にまとめましょう。
また、日本語よりも英語のほうがトークン効率が良いため、ローカルでLLMを動かすシビアな条件下では英語で書いたほうが最終的に性能が低下しづらくなります。カスタム指示はチャットごとに読み込まれるので、ここを節約できるとかなりお得です。同じ指示を日本語と英語で指示を出したときの違いをお見せします。
「でも英語で書くのは面倒……」という方は、日本語で書いた指示をChatGPTに英訳させましょう。AIを使うためにAIを使うという本末転倒感が凄まじいものの、これが一番楽です。AIに頼りすぎて日本語が書けなくなった僕が、AIに英語を書かせて効率化を図る。もはや何も自分で書いていません。
知っておくと便利な設定項目
プリセット以外にも、用途に応じて調整したい設定があります。
temperature(創造性の調整)
modelタブを選択し、Temperatureの項目を操作してみましょう。この数値を変えることで、同じ入力に対してどの程度回答にランダム性を持たせるかを調整できます。
- 低い値(0.1〜0.3):毎回似た出力になる。議事録要約やメール分類など、安定した結果が欲しい場面に最適
- 中程度(0.5〜0.7):バランスの取れた出力。通常の対話に推奨
- 高い値(0.8〜1.0):毎回異なる出力になる。小説の執筆やアイデア出しなど、創造性が求められる場面向け
これもプリセットに保存できるので、「議事録要約モード(Temperature: 0.2)」「創作モード(Temperature: 0.9)」のように使い分けると便利です。
reasoning effort(推論レベル)※gpt-ossなど特定のモデル限定
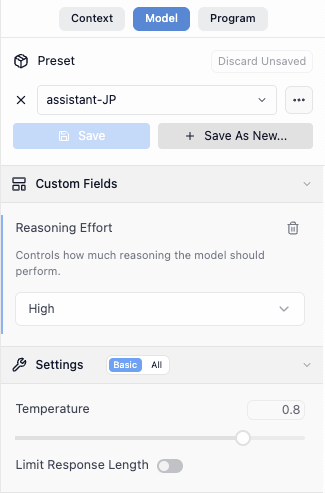
gpt-ossを使用している場合、設定アイコンからmodelを選択することで、Reasoning Effortの段階を設定できます。これは、AIがどの程度じっくり考えてから回答するかを調整する機能です。
レベルを上げると回答の精度が向上する可能性がありますが、そのぶん処理時間が長くなります。複雑な問題解決や論理的な分析が必要な場面では高めに、簡単な質問には低めに設定すると効率的です。
「うちの会社でもAI使いたいんだけど……」という方へ
ローカルLLMを試してみて「これ、もっとちゃんと業務で使えないかな?」と思った方、いませんか?
個人で使うのと、会社全体で導入するのとでは話が変わってきます。セキュリティポリシー、既存システムとの連携、従業員の教育……考えることは山ほど。
そんなときは、AI導入のプロに相談するのが一番の近道です。私たちは企業のAI活用を、要件定義から運用まで一貫してサポートしています。
「とりあえず話だけでも聞いてみたい」という段階でも大歓迎です。まずはお気軽にご相談ください。
- “今できること”より”次に何を経験したいか”から逆算して案件提案
- 実装の現場感覚を持つ担当者が、案件の実態まで把握してマッチング
- モダン技術、AIに前向きな企業との接点が豊富
登録・相談は完全無料。情報収集だけでもお気軽にどうぞ!











