
初めまして、ブリッジディレクターのJun/小南淳子です。
みなさまはどのようにして地球ができたのか、木星がどうして現在の場所に落ち着いたか、ご存じでしょうか? 私はそのようなことに対する答えを得るために、以前は大学で長いこと研究員をやっており、コンピュータシミュレーションを通じて大量のデータを処理する作業といったようなことをしていました。
さて、「データがたくさんある」という状態。これは、ガラクタがたくさんある、という状態と似ています。それを分別して、分類すれば、もしかしたらダイヤモンド級に価値のあるものを発見できるかもしれません。
意味のないデータの蓄積やASCIIの山に魔法をかけると、そこから「傾向」「うまくいかない理由」「これからの指標」などが生まれてきます。この「魔法」がデータマイニングです。その魔法のうちの一つに、簡単なものに近似曲線を導出する、というものがあります。今回はそれについてのお話です。
想定するケース
時系列のデータが存在するとします。どのようにデータが時間によって変化するのかを知りたい、という場合はたくさんありますよね。身近なところでは、ある商品の値段が時間によってどのように変化するのか、などというものが挙げられます。
変化の仕方を関数で表すことができれば、これからその商品の値段がどのように変化するか予想をすることができます。
データの分布を関数に近似する必要性
データをプロットする(入れ込む)
プロットの仕方も考えないといけません。X軸に何を取るか、Y軸に何を取るかを吟味し、何のデータを見たいかを決めます。例えば、Y軸にプロットされる事象の時間進化をみたい場合は、X軸には時間をとります。
関数(曲線や直線)で近似
常に「すべて」の時間のデータがあるわけではありませんよね。しかし、既存のデータから「流れ」のようなものを推測することはできます。それが関数を使った近似をすることで可能になります。
データのないところのおよその値を知りたい
近似した関数を使うと、この流れで行くなら、この時間にはデータはないが、おそらくこのくらいの値になるだろう、と見当をつけることができます。データの流れや傾向を掴むこと以外にも見えないデータの補間をすることができます。
Python
データを扱う言語は様々ありますが、その中で人気なのがPythonです。コンパイルいらずで、便利なライブラリが揃っているということもあります。筆者は十数年間C言語でなんでも行ってきたのですが、Pythonを知り、その便利さに驚きました。今回はPythonを使い、お話を進めていきたいと思います。
Python2とPython3 の主な違い
Python には昔ながらのPython2とちょっと新しいPython3があります。以下に大きな違いを列挙します。
printの違い
Python2ではprint の後に()は必要ありませんでしたが、Python3では必要になりました。
ライブラリの違い
実はまだPython3で用意されているライブラリの数のほうがPython2で用意されているライブラリの数より少ないです。しかし、標準ライブラリは揃っているので大体大丈夫です。
数値の扱いの違い
Python3で数値を扱うときは小数点まで表示されます。Python2で自動的に切り捨てられる小数点以下、Python3では切り捨てられずに表示されます。
int型の扱いの違い
Python3ではint型からlong 型が廃止されました。int型の上限がなくなり、long型で扱える数値をint型で扱えるようになりました。
例外構文の違い
except 文を使うときにpython2では「,」を使っていたところが「as」になりました。Python2とPython3の違いの詳細に関してはこちらを参考にしてください。
上記をふまえ、私がPython3を使う理由は下記の通りです。
- コードが短く描けるため
- Python3のライブラリが整備されてきたため。一方python2からPython3へ移行するのが大変になってきました。
- Python2のサポートは既に終了しているため。
Python3 のインストール
Python3がプリインストールされている場合、そのまま使いましょう。しかし、Python2しかない場合、Python3を入れましょう。
ここではHomebrewを使ったインストール方法を紹介します。XCodeコマンドラインツールがインストールしてあることが前提です。
- Homebrewのインストール
- brewコマンドを実行してインストール
ターミナルで下記を実行します。
/bin/bash -c “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)”
brew install python
Anaconda のインストール
他のNumpy やSciPyもインストールしたいという場合、簡単なのがAnacondaをインストールしてしまうことです。Anacondaのサイトに行き、Mac用のパッケージをダウンロードしてインストールしましょう。
Python3の使い方
ターミナルからpython3→return と入力すると始まります
下記のように「>>>」が出てきたら準備ができたということです。
>>>a=10
>>>b=20
>>>a*b
200
AnacondaのナビゲータからJupyterをローンチさせて使います
どちらもインタラクティブに使えて便利ですが、今回はJupyterを使ってみることにしましょう。ちなみにJupyter の読み方は、正しくは「じゅぱいたー」ですが、どうしても「ジュピター」の方が読みやすいのでそちらが浸透してしまっているらしいです。
Anaconda をインストールし、Jupyter をローンチさせると以下のような画面になります。

右上の「新規」から「Python3」をクリックすると以下のような画面が出てきます。

四角の中にコマンドを記入していきます。shiftを押しながらreturnを押すと次の四角に移ることができます。
グラフ内の点を一次補間することで近似曲線を描いてみましょう
データを作成してみて、それに合う近似曲線が、本当に作成したデータを表しているものか確認します。まず以下のようにデータを作成します。
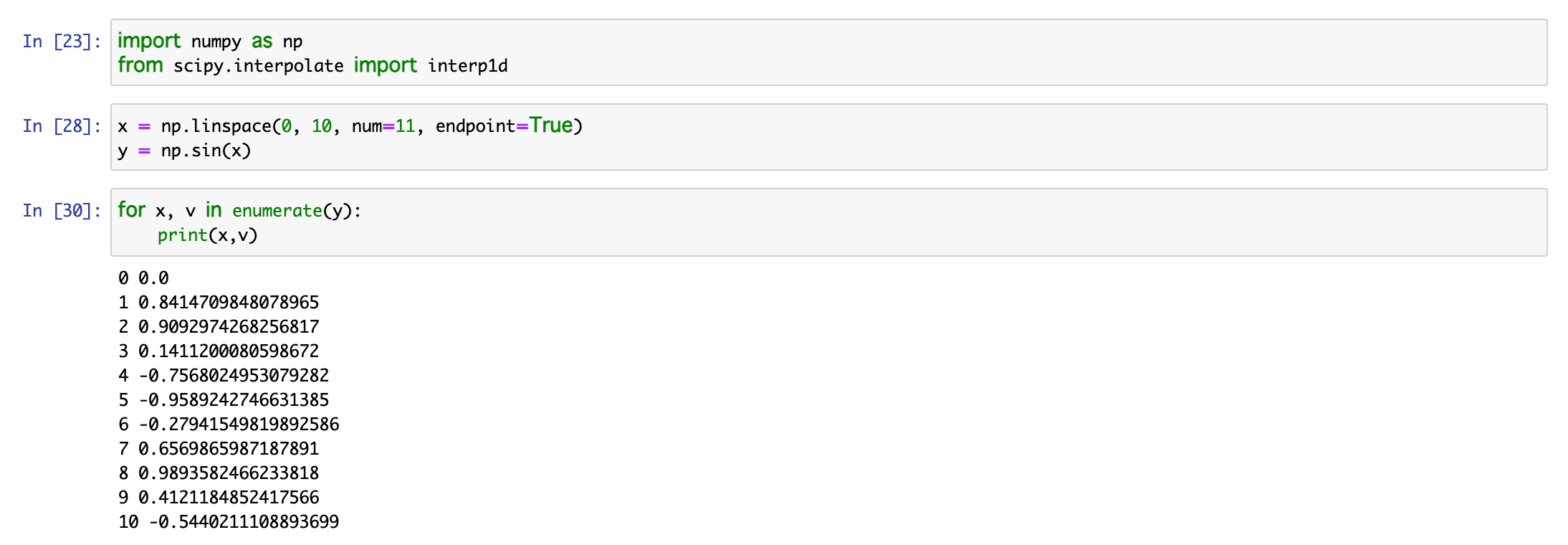
最初に2行でnumpy をインポートし、SciPyも使えるようにします。xは0から10まで整数値をとるものとし、yの値としてはsin(x)の値をとるものとします。つまり、近似曲線がサインカーブを描いてくれればこの実験は成功ということになります。
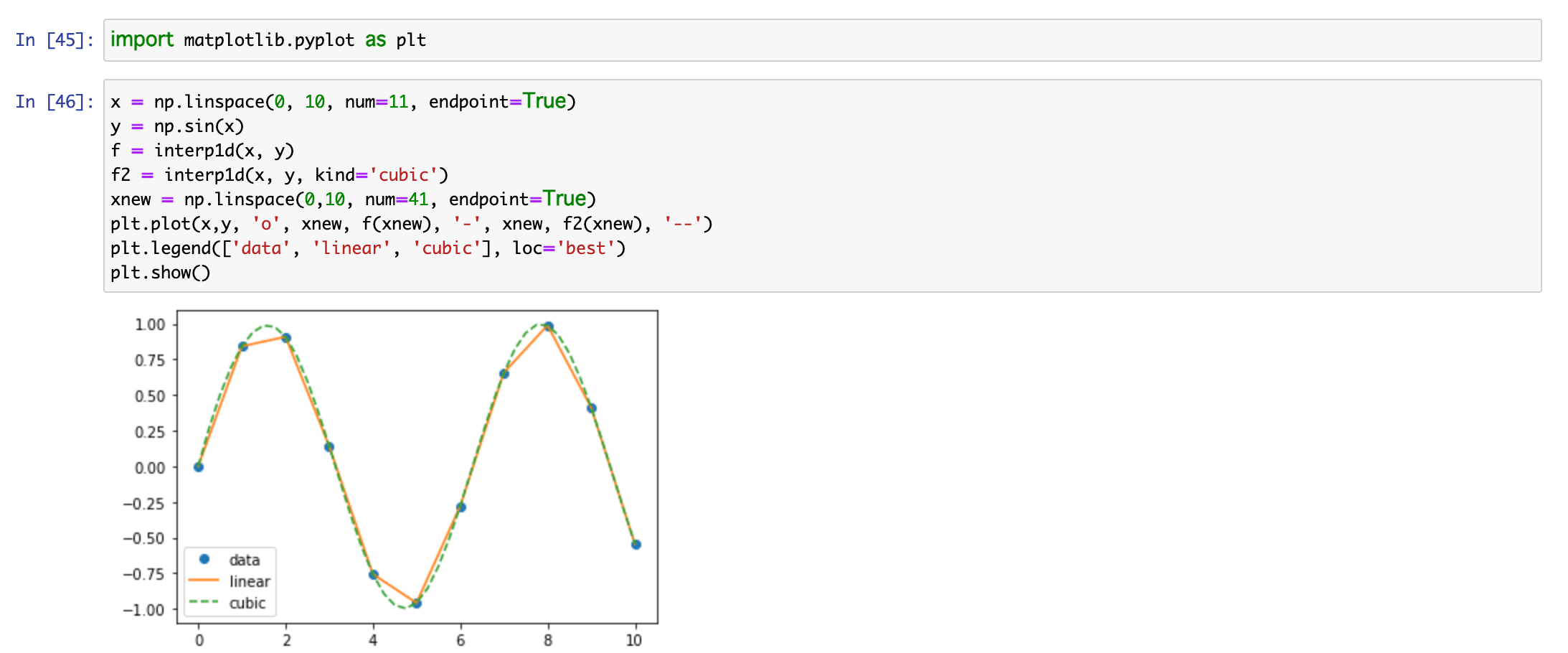
図をプロットするためにmatplotlibを呼び出しました。interp1dを使い、近似曲線をひきます。ご覧の通り引いた近似曲線(破線)はたしかにサインカーブを描いています。実験成功、ということになります。
では、xの値はそのままでyの値は、0-10までの範囲で適当に選んでましょう。それでもデータを滑らかに繋ぐ近似曲線が引けるか実験してみます。
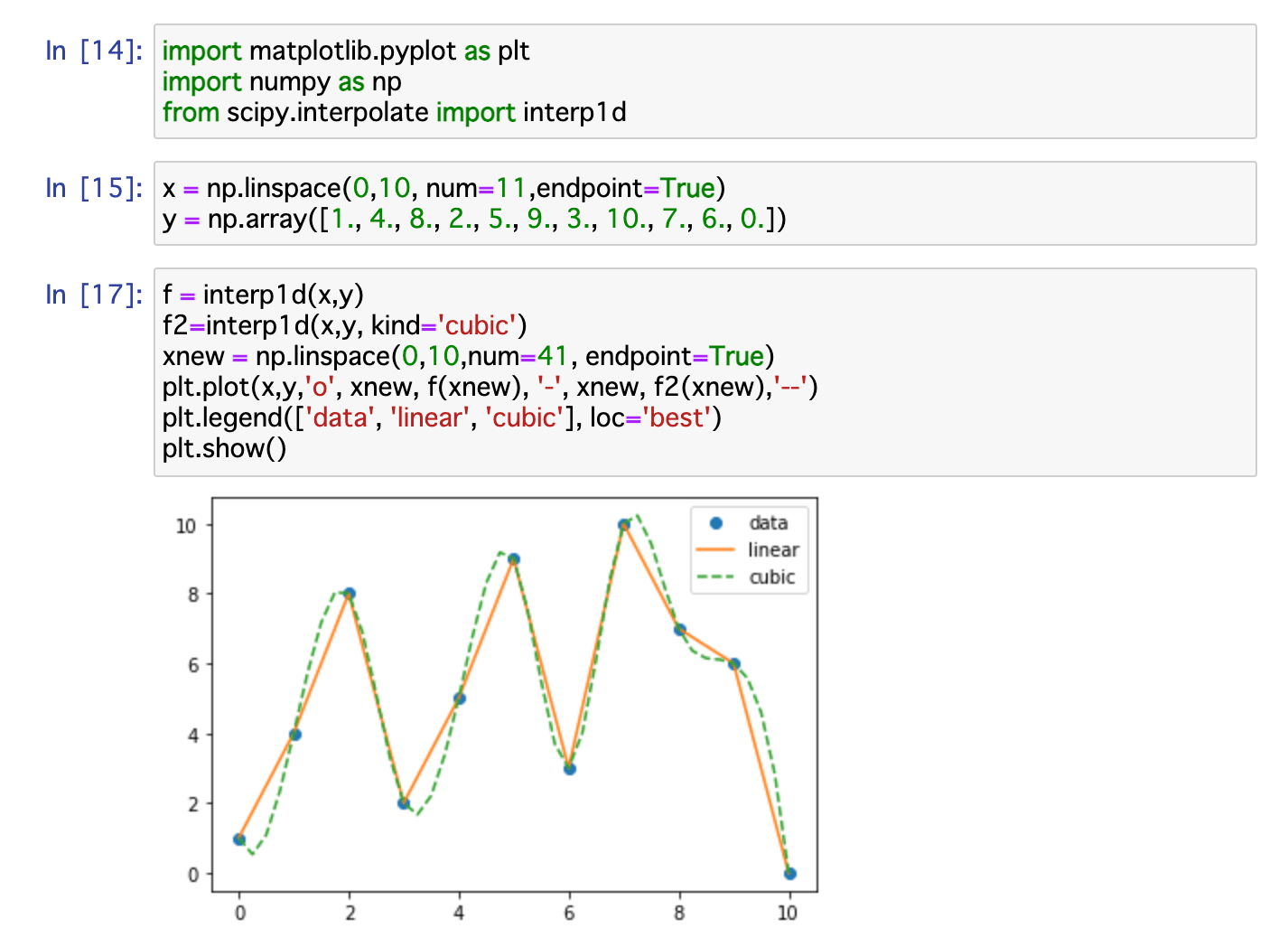
無事引けたので実験成功です。
データから近似曲線が引けると、そのデータの傾向が把握しやすくなります。また、データがない部分でも、値の類推ができます。今回は曲線で近似をしましたが、データのばらつきを色で示したりすることも可能です。
データがどのような傾向を持っているのか、データから私たちは何を学べるのか、pythonを使うことでグッと身近になりました。ただのデータの山は宝の山になり、会社の経営方針を変えるものにもなり得るのです。データって怖いですね。











