
こんにちは、新卒エンジニアの鈴木です。
皆さんググっていますか? 最近はAIの勢いがすごく、Z世代のなかでは「チャピる」という言葉も一時期流行りましたね。とはいえ、ブラウザはまだまだ必要不可欠な存在です。ブラウザを開かない日なんてありませんし、Webエンジニアとしてブラウザが画面を表示するまでの仕組みをちゃんと知っておきたいと思いました。
この記事では、URLを入力してから画面が表示されるまでの流れを、順を追って整理していきます。
Web開発を始めたばかりの方や、なんとなくブラウザを使っているけど裏側が気になる方に向けて書いているので、読み終えるとDNS・TCP・TLS・HTTPといった用語の意味と、それぞれがどのタイミングで何をしているかがわかるようになります!
全体の流れをざっくり把握する
細かい話に入る前に、まず全体の処理の流れを頭に入れておくと、各セクションで「これは何のための話か」が理解しやすくなります。
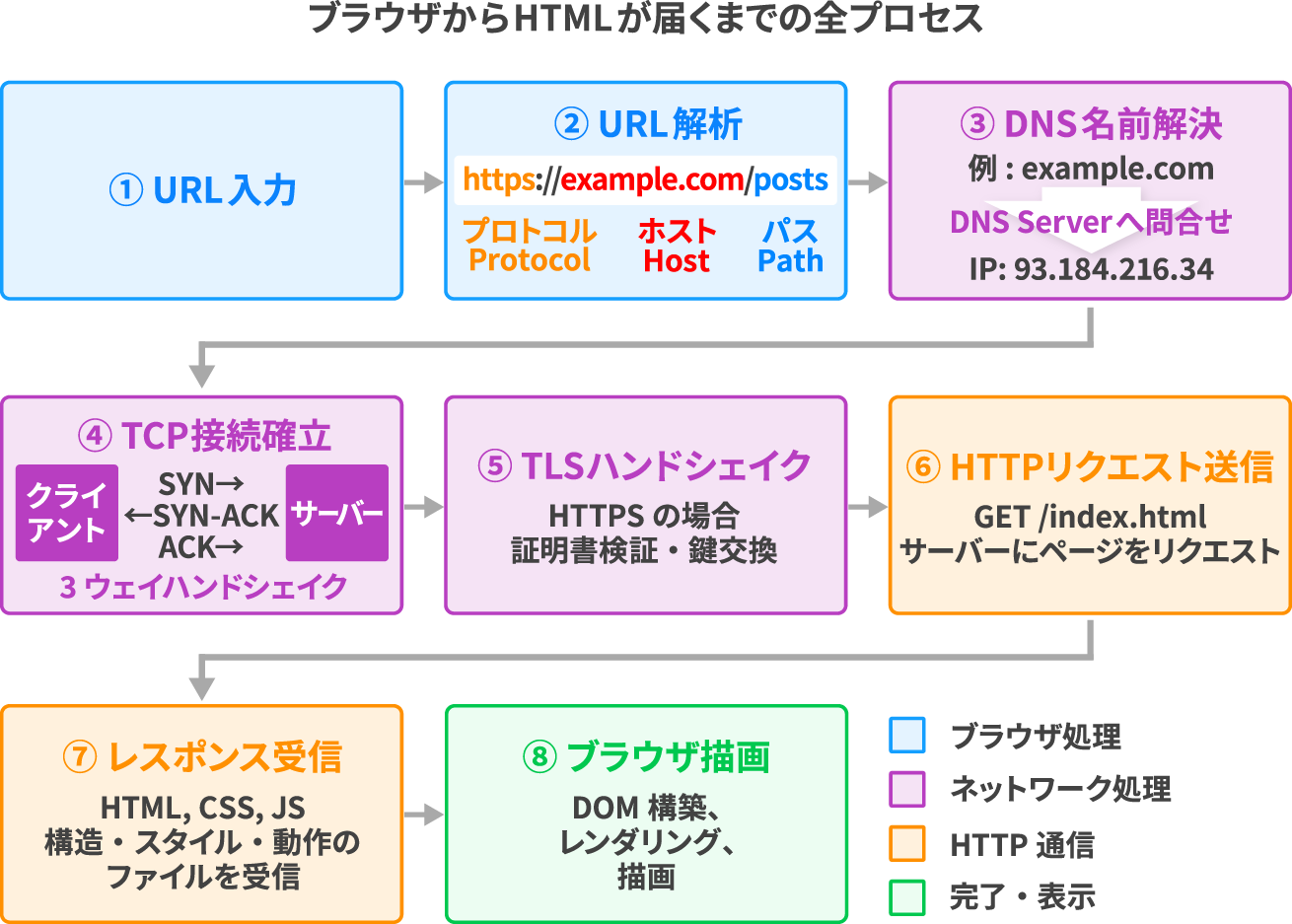
大まかには、次の順番で処理が進みます。
| ステップ(画像での番号) | やること | 電話に例えると |
|---|---|---|
| ① URLの解析(1、2) | URLをバラして、どこに何を取りに行くかを把握する | 電話をかけたい相手の名前を確認する |
| ② DNS解決(3) | ホスト名(ドメイン名:example.com)をIPアドレスに変換する | 名前から電話番号を調べる |
| ③ TCP接続(4) | サーバーと通信路を確立する(3ウェイハンドシェイク) | 電話をかけてつながる |
| ④ TLSハンドシェイク(5) | 通信を暗号化するための準備をする(HTTPSのみ) | 盗聴されない暗号回線に切り替える |
| ⑤ HTTPリクエスト(6) | サーバーに「このページをください」と送る | 用件を伝える |
| ⑥ ブラウザ描画(7、8) | 受け取ったHTMLを解析して画面に表示する | 返答を受け取って内容を理解する |
| ⑦ TCP切断 | 通信が終わったら接続を閉じる(4ウェイハンドシェイク) | 電話を切る |
では、一つずつ見ていきましょう。
1. ブラウザが最初にやること:URLを「解釈する」
Webサイトを見るとき、URLを入力するかリンクをクリックしますよね。ブラウザはまずそのURLを解析して、どのドメインか、どのパスかを特定します。
URLの構造
https://example.com/posts?id=1のようなURLには、通信に必要な情報がすべて含まれています。
各要素の役割は以下のとおりです。
| 要素 | 例 | 役割 |
|---|---|---|
| プロトコル | https |
どのプロトコルで通信するかを示す。httpのデフォルトは80、httpsは443。※ポートとは、1台のサーバーが複数のサービスを同時に受け付けるための窓口番号のようなもの |
| ホスト名(ドメイン名) | example.com |
アクセス先のサーバーを示すドメイン名。この後のDNS解決でIPアドレスに変換される |
| パス | /posts |
サーバー上の、どのリソースを取得したいかを示す |
| クエリパラメータ | ?id=1 |
?以降の追加情報。キーと値のペアでサーバーに渡される |
余談ですが、Webサイト上のリンクをクリックしたときに付く#sectionのようなフラグメント識別子(ページ内リンクの#以降)は、サーバーには送信されず、ブラウザ内のページ内ジャンプにのみ使われます。
2. DNSで住所を調べる
URLを解析して「ユーザがどのドメインにアクセスしたいのか」がわかりました。しかしコンピュータは、example.comのような文字列では通信できません。
実際に通信するには93.184.216.34のような数値の「IPアドレス」が必要です。この「ドメイン名 → IPアドレス」の変換を担うのが、DNS(Domain Name System)です。
「インターネットの電話帳」とよく表現されますが、ドメイン名が「名前」、IPアドレスが「電話番号」とイメージしておくと良いでしょう。
DNS解決の詳細フロー
IPアドレスを探すとき、いきなりDNSサーバーに問い合わせるわけではありません。まずキャッシュを順番に確認し、それでも見つからなかった場合にDNSへの問い合わせが始まります。
では、具体的な流れを順番に見ていきましょう。
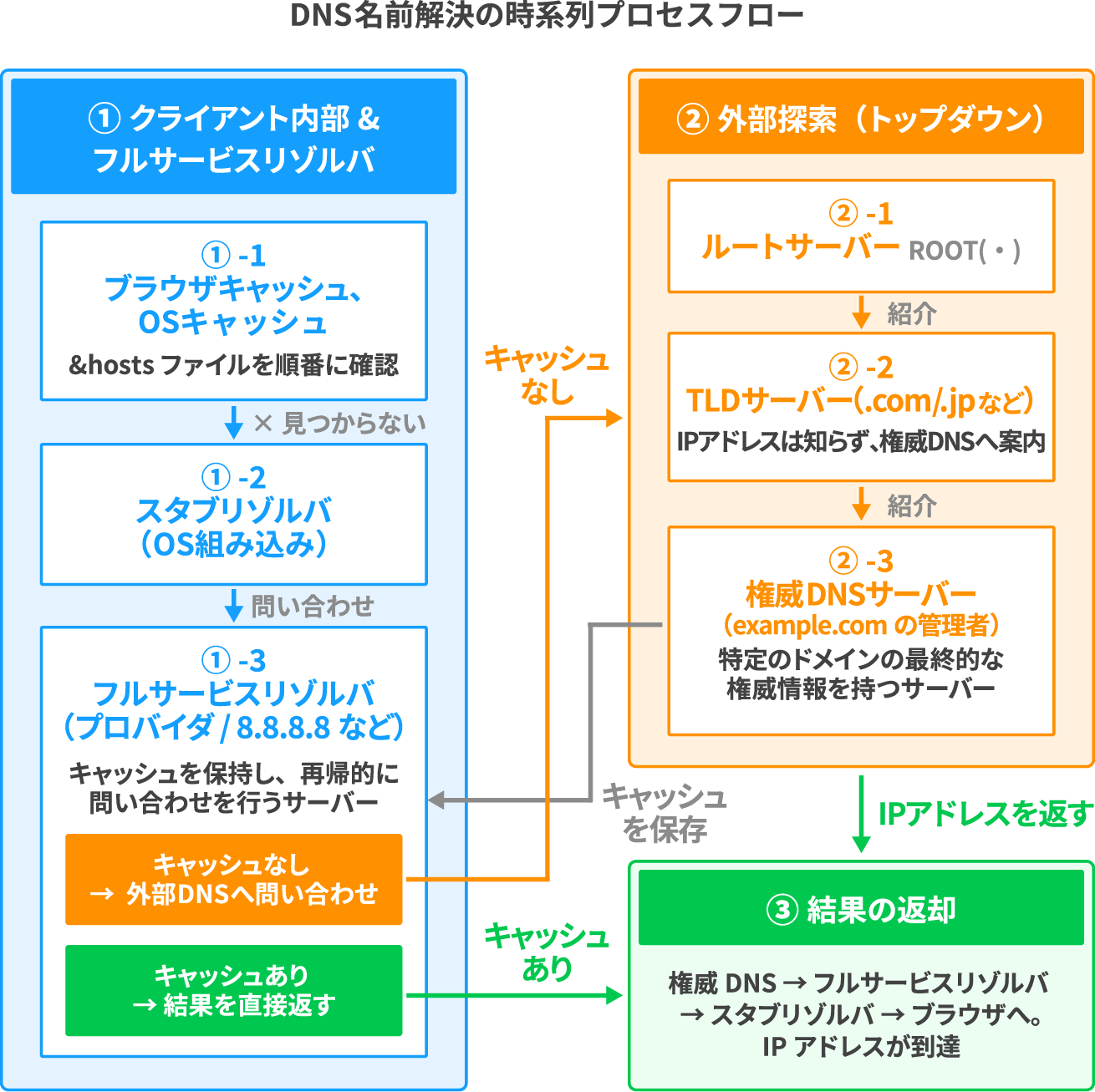
① キャッシュの確認(ブラウザ → OS → hosts)
まずはキャッシュを確認します。キャッシュとは、以前アクセスしたサーバーの情報を手元に残しておく仕組みで、IPアドレスが残っていれば②以降のDNS問い合わせをすべてスキップできます。
ブラウザキャッシュ・OSキャッシュ・hostsファイルの順に確認し、見つかった時点でそのままTCP接続に進みます。
② スタブリゾルバへ問い合わせ
キャッシュで見つからなかった場合はDNSへの問い合わせが始まります。ブラウザ自身が直接DNSサーバーに問い合わせるわけではなく、OSに組み込まれた「スタブリゾルバ」というプログラムが代わりに動きます。
スタブリゾルバは問い合わせを中継する窓口のような役割で、実際の名前解決はここから先のサーバーが担います。
③ フルサービスリゾルバへ転送
スタブリゾルバは、プロバイダやGoogle(8.8.8.8)などが提供する「フルサービスリゾルバ(キャッシュDNSサーバー)」に問い合わせます。フルサービスリゾルバは実際に各DNSサーバーを回ってIPアドレスを調べてくれる調査役です。
ここにキャッシュがあれば、即座にIPアドレスが返されます。
④ ルートサーバー・TLDサーバーへ問い合わせ
フルサービスリゾルバのキャッシュにもない場合、DNSの階層構造をたどる旅が始まります。
以下の図で、詳しい流れを確認してみましょう。
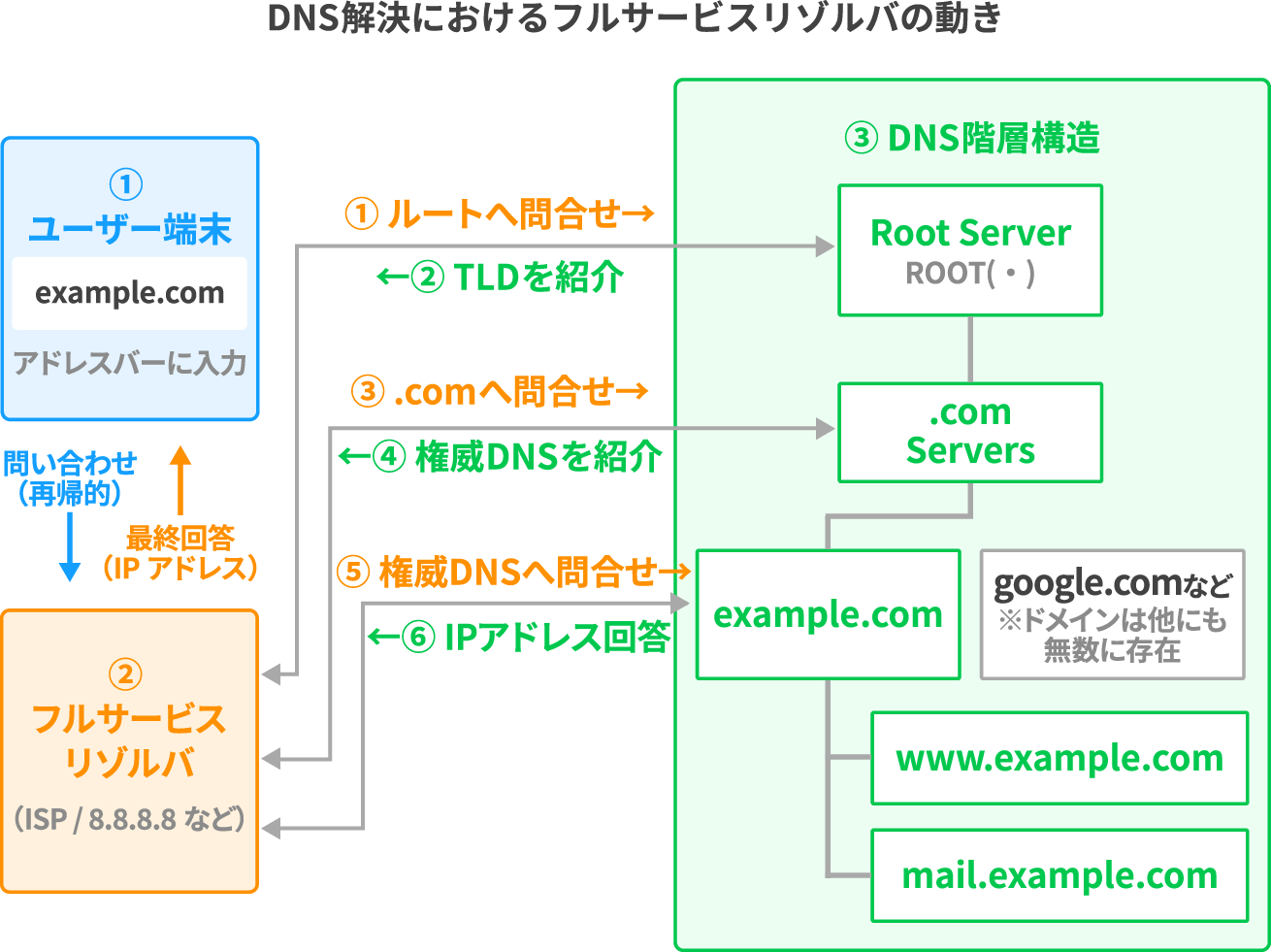
まず最上位の「ルートサーバー」に問い合わせます。ルートサーバーはIPアドレスそのものは知らず、「.comのことはTLDサーバーに聞いて」という案内だけを返します。
次にTLD(Top Level Domain)サーバーに問い合わせます。TLDとはドメイン名の末尾にあたる部分(.comや.jp)のことです。
TLDサーバーもIPアドレスは知らず、「example.comのことは権威DNSサーバーに聞いて」という案内を返します。このようにDNSは、「ルート → TLD → ドメイン固有」という階層構造になっており、各サーバーは自分の管理範囲の情報だけを持ちます。
⑤ 権威DNSサーバーへ問い合わせ
権威DNSサーバーとは、ドメインの最終的な管理者が持つサーバーです。ここで初めてexample.com → 93.184.216.34というIPアドレスが返されます。
⑥ 結果をキャッシュしてブラウザへ返す
フルサービスリゾルバは取得したIPアドレスをTTL(Time To Live)の期間キャッシュし、スタブリゾルバ経由でブラウザに返します。これでブラウザは目的のサーバーのIPアドレスを手に入れ、次のTCP接続に進むことができます。
TTLは「このキャッシュを何秒間有効にするか」を示す値です。TTLが切れる前は再問い合わせが発生しないため高速ですが、DNSの設定を変更してもTTLの期間中は古いIPアドレスが使われ続けます。
3. TCPで「接続」を確立
DNSからIPアドレスが手に入ったので、いよいよそのサーバーと接続を試みます。ここで出てくるのがTCP(Transmission Control Protocol)です。
TCPとは、データを確実に届けるための通信プロトコルです。インターネット上のデータは小さな「パケット」に分割されて送られますが、TCPはそのパケットが順番どおりに、欠けることなく届くことを保証します。
TCPは、通信の階層モデルで見ると整理しやすいです。
-
- アプリケーション層:HTTP, TLS, DNS
- トランスポート層:TCP, UDP← この記事で解説するTCPはここに位置する
- インターネット層:IP
- ネットワークインターフェース層:Ethernet, Wi-Fi
TCPはこのモデルの「トランスポート層」に位置します。一つ上の層にあたる「アプリケーション層」ではHTTPやTLSがデータのやり取りを担い、その内容をTCPに渡します。
TCPはそのデータをパケットに分割し、確実に届くよう管理しながら一つ下の「インターネット層」に渡します。インターネット層ではIPがパケットをどの経路で届けるかを決め、「ネットワークインターフェース層」が実際に電気信号として送り出します。
上の層からデータを受け取り、下の層に渡すことで通信が成り立っています。
では具体的にTCPが何をするかというと、接続する前にまず「ちゃんと通信できる状態か」をお互いに確認し合います。これが次の3ウェイハンドシェイクです。
3ウェイハンドシェイクで接続を確立する
それでは実際に接続する様子を見ていきましょう。TCPの接続確立は「3ウェイハンドシェイク」と呼ばれる3ステップで行われます。

ステップ1:SYN(同期)
クライアントが「接続したい」という意思を示すSYNパケットをサーバーに送ります。このとき、クライアントは自分のシーケンス番号(ISN)をランダムに決めて送信します。
シーケンス番号とは「自分が何バイト目のデータを送っているか」を示す番号で、パケットの順序管理に使われます。
ステップ2:SYN-ACK(同期・確認)
サーバーがSYNを受け取り、「了解、こちらも準備できた」としてSYN-ACKを返します。SYN-ACKにはクライアントのシーケンス番号に+1した確認応答番号と、サーバー自身のシーケンス番号が含まれます。
ステップ3:ACK(確認)
クライアントがサーバーのSYN-ACKに対してACKを返します。これで双方向の通信路が確立されます。
では、なぜ3回なのでしょうか?
2回だと「クライアント → サーバー方向」の通信路しか確認できません。サーバーからクライアントへの逆方向も確認するために、合計3回のやり取りが必要になります。
双方向通信の確立に必要な最小手順が、「3ウェイ」というわけです。
4. TLSハンドシェイクで暗号化通信を確立する
TCPで通信がつながりました。しかし接続を確立しただけでは暗号化されていないため、盗聴された場合に内容を第三者に読まれてしまいます。
このままだとパスワードやクレジットカード番号が危ない。そこで登場するのがTLS(Transport Layer Security)です。
TLSは通信内容を暗号化するプロトコルで、HTTPにTLSを組み合わせたものがHTTPSです。URLがhttps://から始まるサイトはすべてこの仕組みで保護されています。
なお、以前はSSL(Secure Sockets Layer)という名称でしたが、現在はTLSに置き換わっています。会話の中で「SSL」と呼ばれることも多いですが、実態はほぼTLSです。
TLSハンドシェイクでは大きく「サーバーの本人確認」と「暗号化の準備」の2つを行います。
サーバーの本人確認:なぜ証明書が必要なのか?
回線はつながっても、本当に目的のサーバーと通信しているかどうかはまだわかりません。悪意のある第三者が途中に割り込んで、example.comのふりをしている可能性があるからです。
これを防ぐのが「サーバー証明書」です。
証明書は「信頼できる第三者機関(CA:認証局)がこのサーバーは本物だと保証した身分証明書」です。ブラウザはサーバーから証明書を受け取り、信頼できるCAが署名したものかを検証します。
証明書の検証フロー
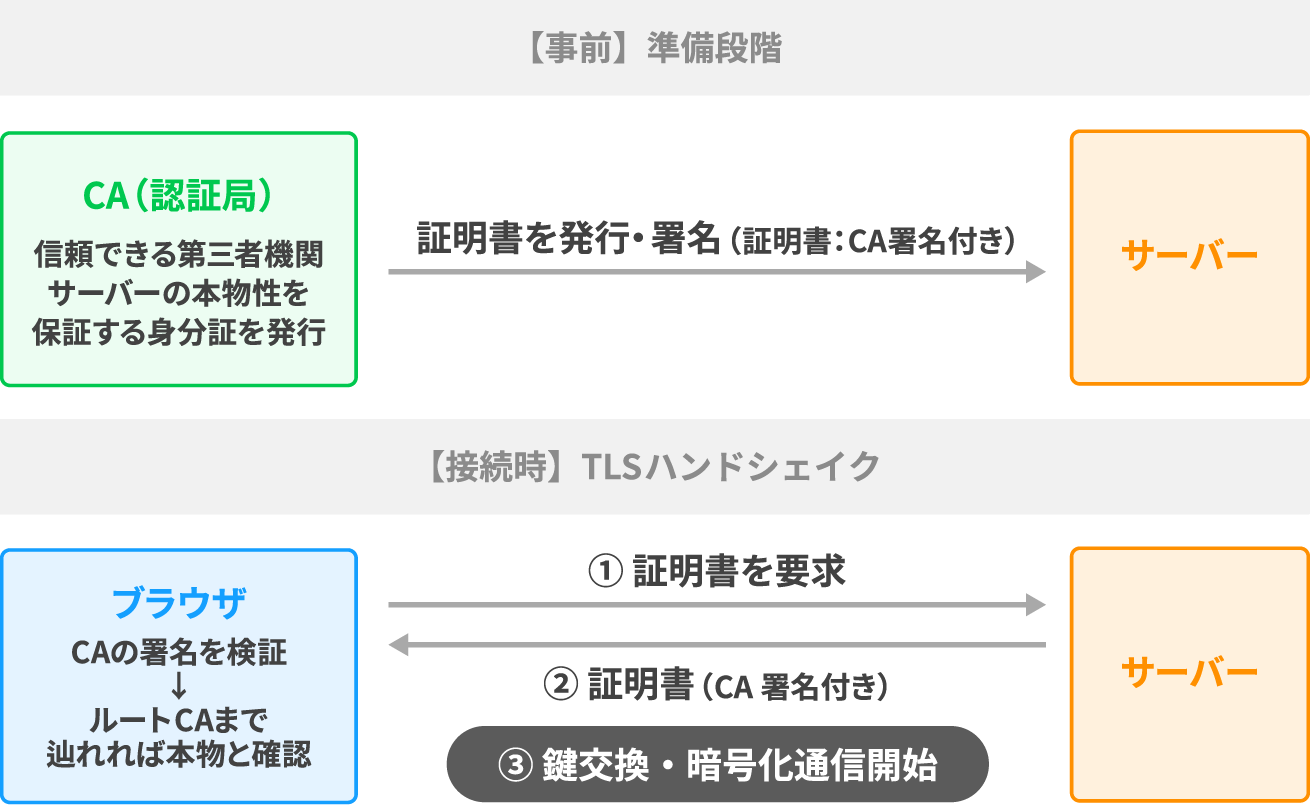
CAには階層構造があります。ブラウザがあらかじめ信頼している「ルートCA」、その下に「中間CA」、そしてサーバーが持つ「サーバー証明書」という順番です。
ブラウザはサーバー証明書 → 中間CA → ルートCAの順に署名をたどり、ルートCAまでたどり着ければ「本物のサーバーだ」と判断します。
再び階層構造の話でたくさん用語が出てきましたね。要するにサーバーは、信頼できる第三者(CA)に本物であることを証明する証明書を発行してもらい、クライアントは証明書を受け取り、OSやブラウザにあらかじめ組み込まれた信頼済みCAリストと照合することで本人確認をしています。
暗号化の準備(鍵交換)
本人確認が済んだら、次は通信内容を暗号化するための「共通鍵」を安全に共有します。暗号化とは、データを第三者に読めない形式に変換する仕組みです。盗聴されても内容が解読できなければ、安全に通信できます。
ただし鍵をそのまま送ると、鍵自体も盗まれてしまいます。公開鍵暗号は安全ですが処理が重く、共通鍵暗号は高速ですが鍵を安全に渡す手段がありません。
そこで「公開鍵暗号の仕組みを使って共通鍵を安全に共有し、実際の通信は共通鍵暗号で行う」という設計になっています。
なお、現在主流のTLS 1.3ではRSA鍵交換は廃止されており、ECDHE(楕円曲線ディフィー・ヘルマン)という方式で共通鍵を導出します。鍵の話だけで1本ブログが書けるほどの内容なので今回は割愛しますが、ぜひ調べてみてください。
ネットワークとセキュリティは強く絡んでいて面白いです。
5. ここまで来てようやくHTTPリクエストが飛ぶ
DNSで住所を調べ、TCPで接続を確立し、TLSで暗号化の準備を整えて、ようやくブラウザはサーバーにHTTPリクエストを送信します。
HTTP(HyperText Transfer Protocol)とは、ブラウザとサーバーがデータをやり取りするためのプロトコルです。DNS・TCP・TLSとここまで準備してきたうえでようやく動き出す、Web通信の本体とも言える部分でしょう。
リクエストの構造
HTTPリクエストは大きく「リクエストライン・ヘッダー・ボディ」の3部構成です。実際のリクエストは以下のような形式で送られます。
GET /posts?id=1 HTTP/1.1 ← リクエストライン(メソッド・パス・バージョン)
Host: example.com ← どのサーバーに送るか
User-Agent: Mozilla/5.0 ... ← 送信元のブラウザ情報
Accept: text/html ← 受け取れるデータ形式
← (空行でヘッダーとボディを区切る)
← ボディ(GETの場合は空。POST等でデータを含む)
各部の役割は以下のとおりです。
| 部位 | 例 | 役割 |
|---|---|---|
| メソッド | GET / POST / PUT / DELETE |
何をしたいかを示す。GETは「取得」、POSTは「新規送信」、PUTは「更新」、DELETEは「削除」 |
| ヘッダー | Host / Authorization / Cache-Control |
リクエストの補足情報。宛先・認証情報・キャッシュ制御などを、キーと値のペアで指定する |
| ボディ | フォームの入力値やJSONデータなど | サーバーに送るデータ本体。GETには通常なく、POSTやPUTで使われる |
レスポンスとステータスコード
サーバーはリクエストを受け取ると、HTMLなどのデータとともにステータスコードを返します。
ステータスコードは3桁の数字で、処理が成功したか・失敗したか・どんな理由かを示します。先頭の数字でおおまかな分類がわかります。
| 分類 | 意味 | 代表的な例 |
|---|---|---|
| 2xx | 成功 |
|
| 3xx | リダイレクト |
|
| 4xx | クライアント側のエラー |
|
| 5xx | サーバー側のエラー |
|
4xxはブラウザ(リクエスト側)の問題、5xxはサーバー側の問題と覚えておくと、エラーが起きたときにどちらに原因があるかをすぐ切り分けられます。
こうしたHTTPリクエストを経てHTMLを受け取ります。ここまでくれば、あとは描画するだけです。
6. ブラウザがHTMLを描画するまで
サーバーからHTMLが返ってきたら、ブラウザはそれを解析して画面に描画します。このフローを「クリティカルレンダリングパス」と呼びます。
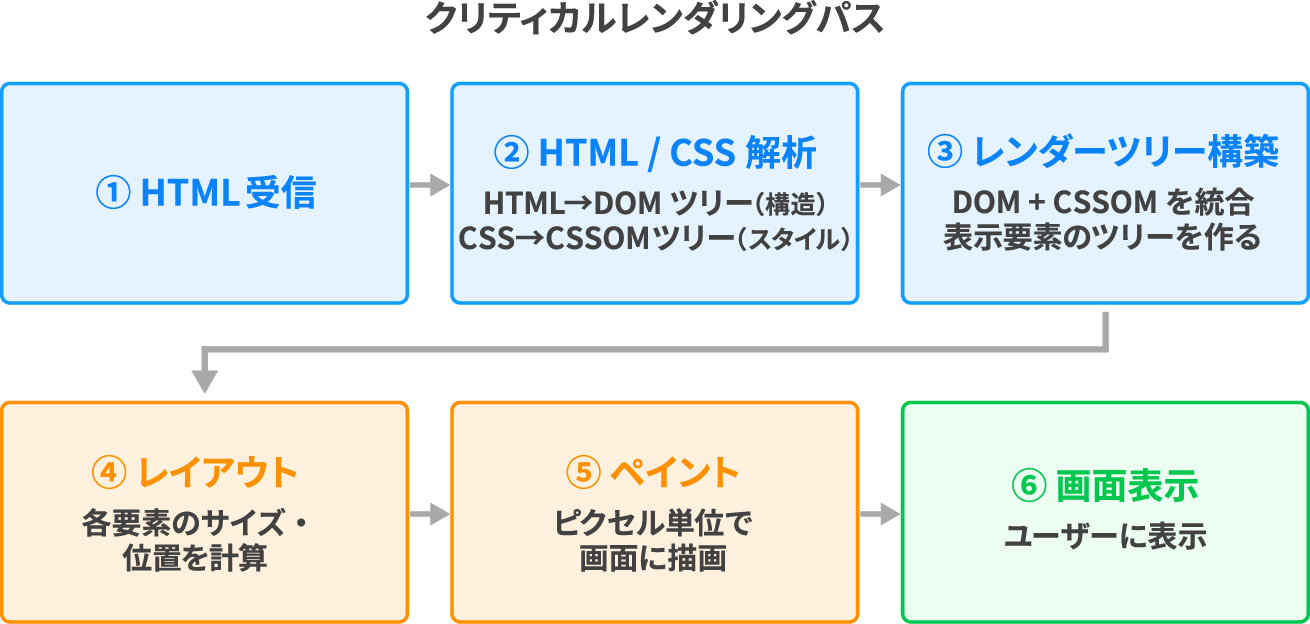
図の左から順に、以下のステップで処理が進みます。
| ステップ | 内容 |
|---|---|
| HTML 解析 | HTMLを読み取り、要素の構造を表すDOMツリーを構築する |
| CSS 解析 | CSSを読み取り、スタイルの構造を表すCSSOMツリーを構築する |
| レンダーツリー構築 | DOMとCSSOMを統合し、画面に表示する要素のツリーを作る |
| レイアウト | 各要素のサイズと位置を計算する |
| ペイント | 計算結果をもとに画面に描画する |
これでHTMLの解析が完了し、ページが画面に表示されます。URLを入力してからここまで、実はものすごい数の処理が走っていたわけですが、これらはすべてミリ秒単位で完了しています。
普段何気なく使っているブラウザの裏側には、こんな仕組みが動いていたんですね。
7. 接続を終了する
通信が完了し、接続が不要になったら、TCP接続を終了します。接続を開くときが3ウェイなのに対し、閉じるときは4ウェイになります。
4ウェイハンドシェイクで接続を終了する
図の流れに沿って4ステップで接続を閉じます。それぞれ詳しく見ていきましょう。

ステップ1:FIN(クライアント → サーバー)
クライアントがサーバーにFINを送ります。「こちらからの送信は終わりました」という合図です。
ステップ2:ACK(サーバー → クライアント)
サーバーがACKを返します。ただしこの時点で、サーバー側はまだデータを送り続けている可能性があります。
ステップ3:FIN(サーバー → クライアント)
サーバー側の送信も終わったら、サーバーがクライアントにFINを送ります。「こちらも送信が終わりました」という合図です。
ステップ4:ACK(クライアント → サーバー)
クライアントがACKを返して、完全に接続が閉じられます。
3ウェイと違って4ステップになる理由は、TCPが双方向の通信路を持っているからです。「クライアント→サーバー」と「サーバー→クライアント」それぞれの方向について独立して終了処理をする必要があります。
なお最後のACKを送った後、クライアントはしばらくTIME_WAITという状態で待機します。「最後のACKがサーバーに届かなかった場合に備えて再送できるようにする」ためです。
まとめ
今回は、URLを入力してから画面が表示されるまでの流れをDNS・TCP・TLS・HTTPの順に追いました。
| ステップ | 主な処理 |
|---|---|
| URLの解析 | プロトコル・ホスト・パスの解釈 |
| DNS解決 | ドメイン名 → IPアドレスへの変換 |
| TCP接続 | 3ウェイハンドシェイクで通信路を確立 |
| TLS(HTTPS) | 証明書検証・鍵交換で暗号化通信を確立 |
| HTTP | リクエスト送信・レスポンス受信 |
| ブラウザ描画 | DOM構築・レンダリング |
| TCP切断 | 4ウェイハンドシェイクで接続を終了 |
以上がURLを入力してからレンダリングされるまでの流れです。3文字英語や専門用語が多くて大変かと思いますが、エンジニアとして知っておいたらいつか得するかもしれませんね。
最後までご覧いただき、ありがとうございました。











